One of the major challenges facing PE rollups today is the process of data unification across portcos. The purpose of this article is to provide an overview of the challenges related to the consolidation of disparate data sources across multiple portfolio companies with multiple source collection systems. It will also cover at a high level the solutions this team has developed to manage these types of complex systems and mitigate the issues that stem from these challenges in prior roles and for previous clients.
Structure
The article will follow in 3 sections that will:
- Characterize the problem: The article will start with an overview and characterization of the challenges related to the consolidation of data sources, as well as a description of the downstream impact these challenges impose.
- Establish solution design principles: The second section will cover the design principles that are key for remediating these issues, as well as their associated costs and tradeoffs.
- Provide practical examples: This article will provide some practical examples using work done by the Snowpack team in previous roles at Flexport and with major 3PL firms.
This article goes fairly in-depth–for those of you looking for a summary, look no further:
Summary
PE firms can drastically reduce the cost and complexity of standardizing data ex facto by focusing on standardizing at the source layer.
- PE rollups have an advantage: They can set a standard across portfolio companies that either standardizes the source systems they use and/or standardizes the method and format in which they deliver data to the PE firm.
- When consolidating data across portcos, work needs to occur at two levels in two stages:
- Source system work should occur first, at the portco level
- Ingestion, transformation, and consolidation second, at the portfolio level.
- PE firms should ensure that source systems are standardized as much as possible prior to ingesting and transforming the data in order to consolidate it.
For the detail-oriented folks, the article starts below:
Section 1: Challenges of data standardization across sources
Sizing the problem: Start with the source
The primary challenge around standardizing data across sources starts at the source, and has to do with the mode of collection of the data. There are two structural factors related to data collection that determine the degree of difficulty in standardizing data across multiple sources:
- The mechanisms for collecting data differ across system and network nodes. (i.e. data is collected via manual entry, automated input, or some other format).
- The systems used to collect the same data are different across network nodes. (i.e. different companies using different software or hardware systems to collect similar data.)
Whenever either of these factors are present, there will always be differences in data quality and data format that need to be addressed when those sources are combined. In addition, the more of these factors that present themselves in relation to one another, the more complex the standardization problem becomes:

Fig. 1: Dual-axis table with collection mechanisms on the vertical axis and the number of collection systems across the horizontal axis. Complexity is multiplicative (number of systems (S) * number of mechanisms (M)).
The challenge described above is essentially a two-axis complexity problem: The collection mechanisms are represented on one axis, systems on the other, and the intersection cells represent the standardization challenge.
The key insight the diagonal captures is that the two factors are not additive, they are multiplicative: One mechanism across many systems is manageable. Many mechanisms across many systems creates an S x M mapping problem where every combination needs its own transformation logic. That bottom-right cell is where most enterprise data standardization pain actually lives.
The chart above only describes the systems for one company. In cases like logistics or private equity, where the challenge is to roll up data across multiple nodes in a network of entities (i.e. supply chain solutions providers, or portcos), this problem is made further complicated by the number of directed connections required to bridge systems across nodes in the network.
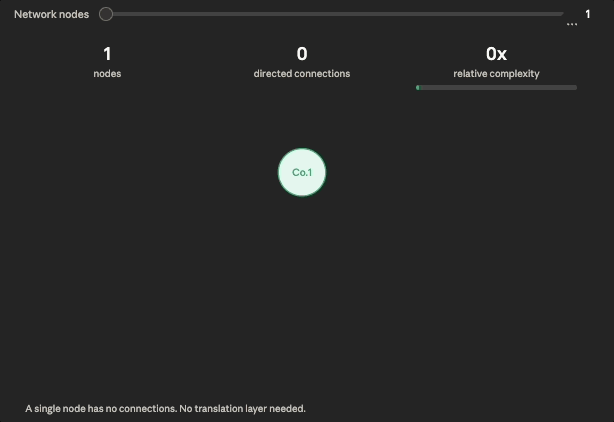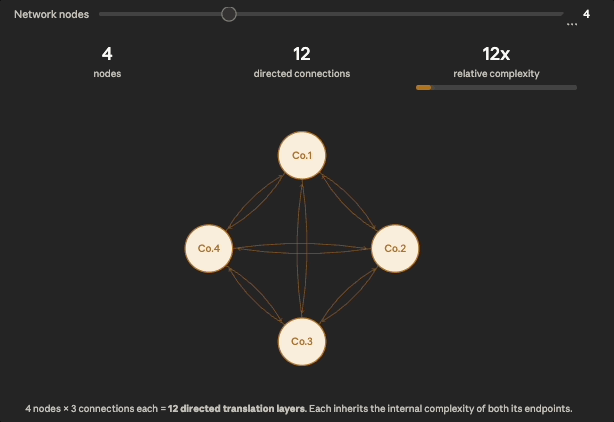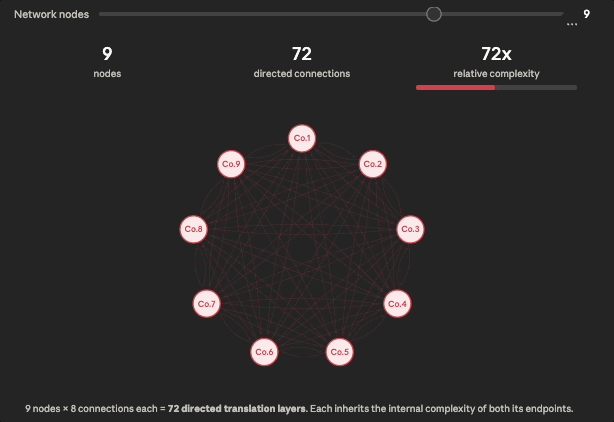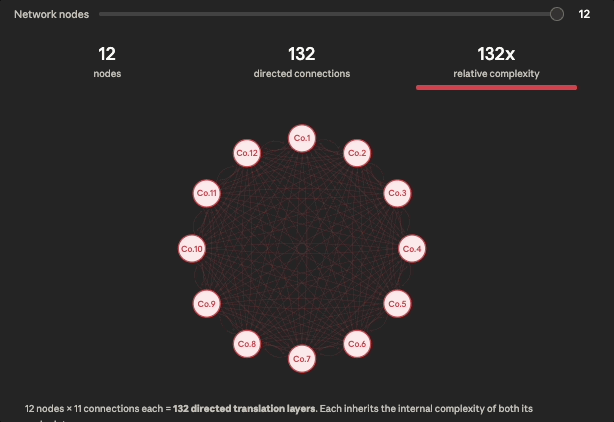
Fig. 2: The number of directed connections across nodes in a network grows as the square of network size (quadratically).
The key number to pay attention to in the visual above is the directed connections count. Three companies feels small, but already means 6 translation layers, each of which potentially inherits the full S x M internal complexity from the first diagram. At 10 companies we have 90 translation layers.
This is the actual scope of a standardization problem in a mid-size logistics network or PE portfolio, and it is why these projects are often scoped incorrectly at first.
Tactical considerations: Moving data from point A to B
The secondary challenge has to do with data delivery: Not every software or system that collects data makes it easy to move that data outside of its native environment and into adjacent systems. There are generally multiple modes of data delivery across systems and companies that need to be reconciled by whatever system is built to consolidate the data.
Modes of delivery that we have seen and worked with include (but are certainly not limited to) the following methods:
- API - data is delivered programmatically via an API call and can be pulled from the source system on an automated basis, requiring no manual intervention.
- FTP - Flat files (i.e. .csv or .json) are dropped into a folder on a cloud server on a regular basis, either manually or using an automated script. From there they can be manually or automatically loaded into a new system.
- Email - Often data in the format of excel documents, PDFs, or CSVs are delivered via email to someone's inbox where they can then be processed manually.
As can be inferred from the list above, any system we build to consolidate data requires us to develop ingestion capabilities that accommodate multiple modes of delivery before we can even begin standardizing the data across nodes.
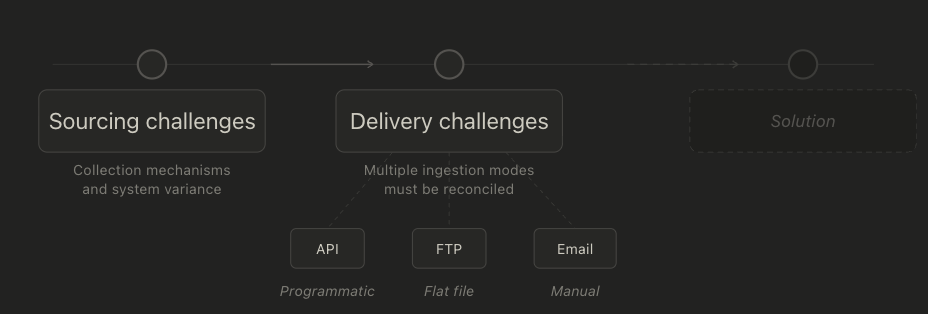
Fig. 3: Sourcing challenges and delivery challenges must be taken into account before a solution can be implemented–before we even start thinking about data consolidation.
Downstream impact: Failing to get off the ground
Failing to properly characterize and address these challenges often leads data consolidation projects across networked entities to stall early.
The standard data infrastructure development process often assumes a bounded number of roughly standardized sources and crucially assumes the presence of a single data environment.
This is often not the case for logistics or in rollups of traditional industries where the data sources are not standardized and the consolidation is actually across multiple data environments at different companies.
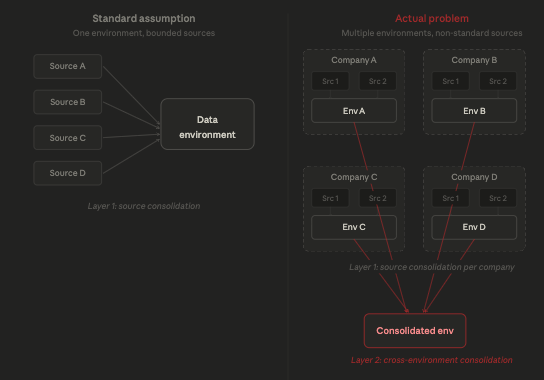
Fig. 4: Rollups of networked entities is a nested problem, meaning it contains a layer of abstraction not present in single-company data consolidation projects.
Addressing these types of consolidation projects following the standard methodology for data consolidation used for individual companies: (Tool selection → Implementation → Data Transformation → Output), fails to account for the degree of complexity inherent in this problem, and prevents us from correctly anticipating and effectively addressing the complexity and associated cost over the length of a given project.
Section 2: Solutions architecture: foundational design principles
The following section will cover the design principles we use to address the challenges described above. This section will be focused on principles rather than technical details. The section will be split into 2 parts:
- Architecture will provide a high-level overview of the solution.
- Planning will address the manner in which we go about designing solutions to address the challenges above, and will cover the following topics:
- Ingestion will address the ingestion of data from multiple complex sources across various methods.
- Transformation will address the process of transforming and standardizing data.
- Delivery will focus on making the standardized data available for downstream use.
Architecture: What data consolidation systems are
Data consolidation systems are just that: a system. They take inputs, perform a function using those inputs, (which in this case is to consolidate and standardize those inputs), and they generate a subsequent output, just like every system ever made.
Though simplistic, this description offers us the overarching structure that we use to plan, design, and categorize the solutions we implement to address each part of that system and ensure that it functions as intended.
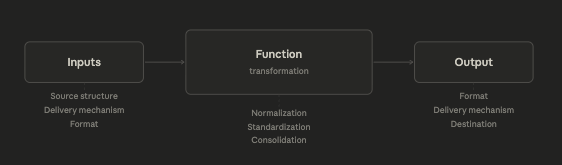
Fig. 5: Simple system structure helps guide us through the categories we need to address to solve data consolidation challenges across multiple nodes of a network.
From this structure we can develop a high-level roadmap for developing data consolidation capabilities across a complex network of entities:
| Category | Name | Description |
|---|---|---|
| Inputs | Source structure | The internal architecture of a source system, including how data is organized, what fields exist, and how consistently they are populated. Variance in source structure across nodes is a primary driver of standardization complexity. |
| Delivery mechanism | The method by which data is moved out of a source system. Common mechanisms include API, FTP flat file drop, and email attachment. Each mechanism requires its own ingestion capability and introduces different reliability and latency characteristics. |
|
| Data format | The file type or schema in which data arrives, such as CSV, JSON, Excel, or PDF. Format inconsistency across sources compounds the translation burden before any standardization logic can be applied. |
|
| Function | Normalization | The process of resolving field-level inconsistencies across sources, such as reconciling different date formats, units of measure, or categorical labels so that equivalent data points can be compared across systems. |
| Standardization | The process of mapping data from disparate source schemas into a common target schema. In a networked environment this must be performed across multiple data environments simultaneously, not just multiple sources within one environment. |
|
| Consolidation | The process of physically combining normalized and standardized data from multiple sources or environments into a single unified data store. In a rollup or logistics network context this is a two-layer problem: consolidation within each node and then consolidation across nodes. |
|
| Output | Data format | The structure and file type in which consolidated data is served to downstream consumers, such as a BI tool, API endpoint, or flat file export. Format must be chosen and/or flexible based on the needs of the destination system. |
| Delivery mechanism | The method by which processed data is delivered to its destination. This mirrors the input delivery problem and must be designed to accommodate the ingestion requirements of each downstream consumer. |
|
| Destination | The system or environment that receives the consolidated output, such as a data warehouse, analytics platform, or operational system. In a multi-node network the destination may itself be one of several environments requiring further reconciliation, or there may be multiple destinations that share the same data warehouse. |
Fig. 6: This table describes each consideration to be addressed and forms the skeleton of a development roadmap for a rollup/consolidation project across network nodes.
Planning: Ingestion, transformation, and delivery
When developing an implementation plan, a substantial amount of discovery work must be done to understand what data is available from each data source and in what format, as well as the manner in which it is available to be delivered before any transformation or movement of data can even occur.
Often, data consolidation projects of this nature require standardizing data across multiple similar sources. As mentioned in the table above, variance in source structure across nodes is a significant driver of complexity in these projects. It is also effectively the source of all other forms of downstream variance and needs to be minimized as much as possible.
There are two ways to minimize variance created by differences in source, either by standardizing source systems or by standardizing their outputs ex facto (once their data has been gathered). The correct solution depends on the structure and format of your network entities, and realistically involves employing a combination of the following methods:
| Method | Example | Benefits | Challenges |
|---|---|---|---|
| Standardizing source systems |
|
Data collection, delivery, and format are all pre-standardized by virtue of the nodes in the network sharing the exact same source systems. This drastically reduces the amount of downstream work required. |
|
| Standardizing data ex facto |
|
Works with existing systems, proprietary (custom) applications that may differ across nodes in the network, or niche systems that may not have a single solution capable of addressing the needs of all nodes comprehensively. |
|
Fig. 7: The method chosen depends on the structure and format of network entities. 99% of the time we end up using a combination of both methods to solve different parts of the problem.
In practice, data consolidation across networked entities always involves the use of both methods. The best course of action is to attempt to standardize the inputs to the data consolidation process at the source as much as possible (i.e. push all portcos onto SFDC), and then use normalization, standardization and consolidation techniques to address the discrepancies that are a product of functional differences between the companies (i.e. the way two firms categorize clients in Salesforce may be slightly different, even if they both use Salesforce).
Data delivery is the last step, and is relatively trivial once the data is standardized and sitting in a data warehouse. The main considerations relate to the destination of the data (i.e. BI tools, data models, AI implementations). The ultimate structure should depend on the end use case, but should also be flexible enough to enable multiple use-cases, from executive/portfolio-level reporting to model training.
Section 3: Flexport's unified data model and 3PL data consolidation
Snowpack Data's founders and a good portion of their staff come from a logistics background, and have worked across environments in which the challenge of standardizing across networked entities is a core problem to be solved.
The main insight derived from our work in the past is that solution design is largely dependent on incentive structure surrounding the data unification process. In this sense, Flexport taught our team a valuable lesson about consolidating data in an environment that lacked the proper incentives for cooperation.
Early days: Flexport's unified platform
The data and engineering organization at Flexport realized early on that one of the primary challenges around managing 3PL processes is the fact that information about the status of a given shipment is often spread across multiple service providers.
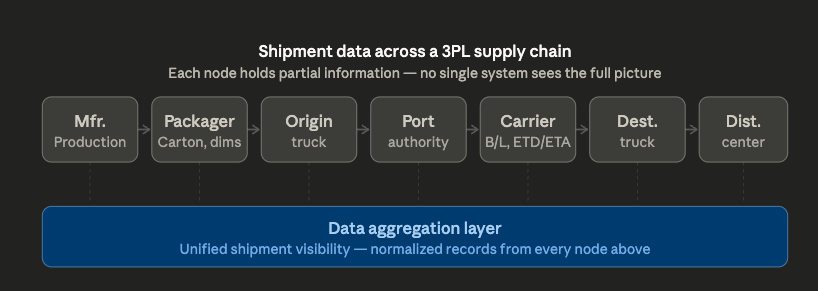
Fig. 8: The manufacturer, packager, trucking company on the origin side, port authority, shipping carrier, destination transportation, and distribution centers all contain valuable information about the supply chain of which they are a part, and of the shipments that move across the chain.
Flexport's initial solution was to build a "control tower" for their customers–a product whose main purpose was to aggregate information across the nodes in their customers' supply chains and present them with an accurate view of when their orders would pass each node along the chain.
The realities of creating a unified data platform
The company's initial play was to encourage customers to push the companies in their supply chain to use Flexport's proprietary software to record information about the status of a given shipment actively.
For example: Instead of entering information into whatever software they were using for their own record-keeping, a trucking company would be required to enter data into Flexport's systems upon successful receipt and/or delivery of a customer's product from one point to another in the supply chain.
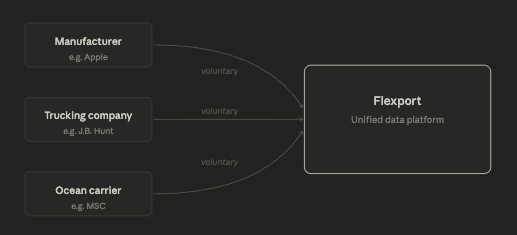
Fig. 9: Flexport's "Happy path diagram" where companies voluntarily enter data about shipments into Flexport's platform in a standardized manner.
The challenge the company quickly ran into was that there was no incentive for companies in their clients' supply chains to use Flexport's software. Even worse: even if they wanted to, many of these companies didn't have any way to deliver that data cleanly or consistently. Many small local logistics firms still rely on paper spreadsheets for operational reporting.
In short, Flexport didn't have the power to force companies to adopt their technology, nor did they have the ability to create incentives that would bring the companies to them. In addition, the format and method in which those companies were capable of delivering data varied wildly across every point in the supply chain, even, in some cases, at the individual company level.
In practice, this creates a network graph of differences in data quality with a degree of complexity to which no other industry on the planet even comes close.
Working against incentives: the mechanical turk
Without the ability to compel partners to use their product, Flexport's solution was to use people to pull that information into their systems, and instead standardize the way in which that information was entered into their proprietary software and processed on the back-end.
At Flexport the data team developed modes of ingestion and unified data models for data coming from:
| Source | Managed by | Detail |
|---|---|---|
| Phone calls | Human | Call transcriptions written to a database, scanned for content and topic, associated with customers and accounts on the back-end. |
| E-mails | Human | Copied into the application, text data written to a database associated with customers and accounts on the back-end. |
| Manual typed entries into the app (multiple languages) | Human | Operators entered information manually into the application, information was scanned, tested for errors, and associated with customers and accounts on the back-end. |
| API connectors | Automated | Where available, we pulled data from APIs directly into back-end production databases where it could then be surfaced in the application. |
| PDFs | Human/Automated | Developed PDF scanning technologies before AI to pull out key pieces of information from customs forms and purchase orders. |
| FTP | Human/Automated | Had thousands of FTP connections set up with clients and shippers that pulled data into both the production and reporting databases. |
| Google documents and spreadsheets | Human/Automated | Connected directly to operators' spreadsheets within the company and pulled that information directly into production and reporting databases. |
Fig. 10: The sources we consolidated across above, which also varied wildly in format.
Ingesting all of this data automatically was functionally impossible at that scale and with that degree of variance, so the ingestion process was effectively handled automatically where possible, and then subsequently by human beings entering data manually into its platform in a pre-determined format.
On the back-end the transformation process was handled by the data and engineering teams, who took the automatically and manually collected data and stitched it together by building a series of complex standardization and transformation layers to form a comprehensive data model usable both by the production application and for internal and external reporting purposes.
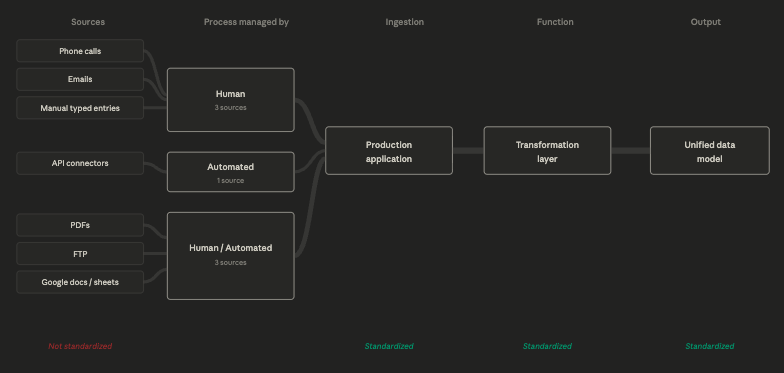
Fig. 11: Flexport couldn't standardize data at the source level, and was operating in an extremely complex environment. Therefore the solution had to be focused on standardization of the ingestion, transformation and output process. At one point, Flexport had over 4,000 unique data models contributing to this process.
Takeaways for PE rollups
Flexport had no ability to standardize the source systems, or compel its partners to deliver data in a standardized format. Because of this, they had to focus on standardizing ex facto. This method is substantially more costly over time than standardizing at the source layer.
PE rollups have an advantage in the sense that they can set a standard across portfolio companies that either standardizes the source systems they use, or at the very least standardizes the method by and format in which they are expected to deliver data to the PE firm. In this sense, PE firms can drastically reduce the complexity of ex facto work required by focusing on standardizing at the source layer.
Implementation considerations
When consolidating data across portcos, work needs to occur at two levels: The source system work should occur first, at the portco level, and the ingestion, transformation, and unification second at the portfolio level.
In practical terms, this means ensuring that source systems are standardized as much as possible prior to ingesting and transforming the data in order to consolidate it. Any project proposals that neglect the first step are likely to incur major frustration and complication and exceed costs and timeline expectations.
Notes
Starting in the wrong place: Tooling selection
Often the first question executives ask for help to address is around tooling selection.
Tooling offerings today generally market towards SMBs and mid-market enterprise firms as plug-and-play solutions, but in doing so often assume that most companies are consolidating data from a standard set of tools, each with their own well-defined APIs.
The average SMB/Mid-market firm will only combine data from a handful of sources, and usually those sources include a CRM (i.e. Hubspot/Salesforce/etc.), a production environment (i.e. website/web application), and a payments provider (i.e. Stripe). These sources almost always have well documented APIs that deliver pre-structured data cleanly to whatever endpoint a user chooses.
Companies using niche or dated tools will often require substantially more custom work to consolidate data sources than these providers imply in their sales and marketing materials for the reasons described above.
Multiply the practical limitations of non-standard systems across a portfolio or a network of suppliers and you'll spend a year and hundreds of thousands of dollars spinning your wheels because you started by picking tools that promised you an out-of-the-box solution for a complex problem.