One of dbt's key value propositions, and ultimately why it effectively became the de-facto standard for data transformation, is that it brought software engineering best practices to data teams. It lets you define & centralize your transformations as code, includes native testing & documentation features, and lets you version-control your logic. And if you're familiar with typical engineering workflows, you know how important of a role CI/CD1 plays. A solid CI/CD pipeline automates the process of integrating your new code into production (including testing & & deployment), and minimizes downtime and the risk of introducing any breaking changes.
Once your dbt project grows beyond a handful of models and you have multiple contributors and users that rely on your analytics models maintained by dbt, you inevitably run into the need for a reliable CI/CD pipeline. There are two primary goals that this will help solve:
- Pre-merge: you want to make sure your code runs successfully in a dev environment and won't break any downstream models
- Post-merge: you want your changes to be picked up and implemented quickly, rather than waiting hours for the next scheduled run (particularly if it's on an infrequent or daily schedule)
The stakes get higher as your dbt project grows and more business users depend on your data, and the last thing you want to do is to accidentally introduce a breaking change that causes your key dashboards and data science models to operate on stale, or even incorrect data. Even a simple CI/CD pipeline can help prevent this.
Okay, but what's "Slim CI"?
The simplest way to make sure all of your new code runs successfully is to build all of the models in your dbt project and ensure everything successfully runs. You could do this, but it would likely be very slow and expensive, and can be frustrating if you only changed 1-2 models as part of your PR and have to wait 15 minutes to rebuild your entire project. Rather than rebuilding your entire dbt project every time you make a change, we recommend setting up your CI job to run & test only the models that you modified in your PR (as well as the downstream models that reference them). The dbt Labs team refers to this concept as "Slim CI".
dbt Cloud supports this pattern natively through their git integration, and their ability to store and manage the "state" in your project. By comparing your PR's changes against the state of the project from the latest production run, dbt Cloud can determine which models were modified and selectively build them.
If you use dbt's open-source core product instead of dbt Cloud, you can still replicate this same kind of pattern -- it just requires a bit of creativity and the right tooling approach. There are many different ways you can accomplish this, but I'm going to show you a couple practical approaches and highlight when a particular approach might make sense depending on your team structure and use cases.
Approach 1: Git-Based CI Solutions
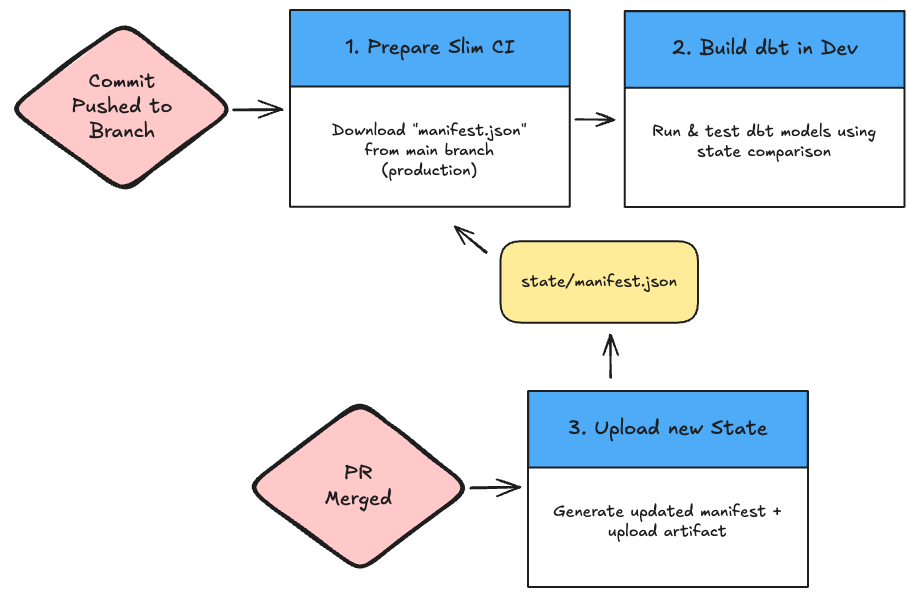
1a: State-Based Detection
dbt's operations are by default stateless and idempotent2, but state-related artifacts are still generated after any dbt command is run. The manifest.json file captures the complete state of your project, including all models & tests. This approach leverages the manifest to compare your code against the latest state -- just like the dbt Cloud approach. The only difference is that you need to manage & store the "state" yourself.
Here's the basic GitHub/GitLab CI pattern:

It's a fairly simple approach, so I'll show you an example of how you might set up your CI pipeline. The example below is for a GitLab job, but can be easily adapted for GitHub. It assumes you're using uv in your project, and that you have already provisioned your GitHub/GitLab service account with access it needs to your data warehouse. As an alternative, you could also set up GitHub/GitLab secrets to pass through a username and password instead as environment variables. You can also purely use pip for the dbt portion if you're not using uv.
Example CI job:
This is the most similar approach to how dbt Cloud handles this, but it requires managing state as an additional artifact in your repo, and requires careful artifact management across pipelines.
1b: Git Diff Detection (Simpler)
A more straightforward approach directly analyzes git diffs to identify changed SQL files, rather than relying on storing and directly comparing against the saved dbt state. As you can see, this simplifies the process quite a bit:
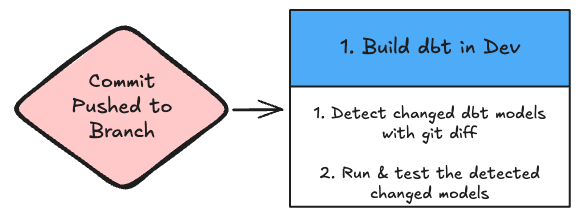
Here is an example of how you might modify & consolidate your job:
# Run Slim CI build of dbt models modified in PR in dev environment
dbt_dev_build:
stage: deploy
variables:
ENV_NAME: 'dev'
GIT_DEPTH: 0
rules:
- if: $CI_PIPELINE_SOURCE == "merge_request_event"
script:
- uv sync
- |
git fetch origin $CI_MERGE_REQUEST_TARGET_BRANCH_NAME
BASE_REF="origin/${CI_MERGE_REQUEST_TARGET_BRANCH_NAME}"
# Detect changed dbt model against base ref for MR
# diff-filter detects renames/copies, and excludes deletions
CHANGED_SQL=$(git diff -M -C --diff-filter=ACMR --name-only ${BASE_REF}...HEAD | grep -E '^models/.+\.sql$' || true)
echo "Changed dbt SQL files:" && echo "$CHANGED_SQL"
if [ -z "$CHANGED_SQL" ]; then
echo "No changed dbt models detected. Exiting."
exit 0
fi
# Convert changed SQL files to dbt model selectors (e.g. changed_model_1+ changed_model_2+)
MODELS=$(echo "$CHANGED_SQL" | xargs -I {} basename {} .sql | sed 's/$/+/' | paste -sd ' ' -)
echo "Slim-style selection: $MODELS"
- uv run dbt deps
- uv run dbt build --target dev --select "$MODELS"
Even without directly referencing the stored state of the dbt project, we're able to replicate the same behavior as Approach 1a. We use xargs to build the dbt selection string, which allows us to pass through the list of changed models, plus their downstream references (e.g. dbt build -s changed_model_1+ changed_model_2+)
This approach works well for testing in dev, but the git diff commands & branch management get more complicated if you want to use this for production runs, particularly around handling merge commits and maintaining proper base references.
Approach 2: Orchestrator-Integrated CI
If you have a larger dbt project with multiple people contributing to it, there's a good chance that you are probably using a designated data orchestrator like Dagster or Airflow. In this situation, Approach 1b can still be helpful for testing against dev, but you likely would not want to use this for building your dbt models in production.
Having most models refreshed through scheduled jobs in your data orchestrator, but some models refreshed via GitHub/GitLab CI runs creates a problematic split. If CI jobs are also building models outside of the context of your orchestrator, you lose the centralized observability and source-of-truth visibility that makes a unified data orchestration platform so valuable in the first place. This becomes a larger issue as you scale: debugging data issues requires checking multiple systems and you lose the complete picture of what's happening with your data pipelines. While likely not an issue for small teams, you also need to consider the security exposure as you scale. In git-based solutions, your CI runners would need privileged read/write access in your data warehouse, which can become problematic if the same service account is shared across multiple repositories or teams.
For good reason, many of our clients are using Dagster as their orchestration tool of choice. We feel that it's the orchestrator best suited for modern data engineering workflows, and we've written before about how Dagster is probably our favorite method for orchestrating dbt. In the next section, I'll show you an example of how we set up an orchestrator-integrated approach to maintain Dagster as the single source of truth for all dbt execution, while still providing the rapid deployment benefits of CI/CD.
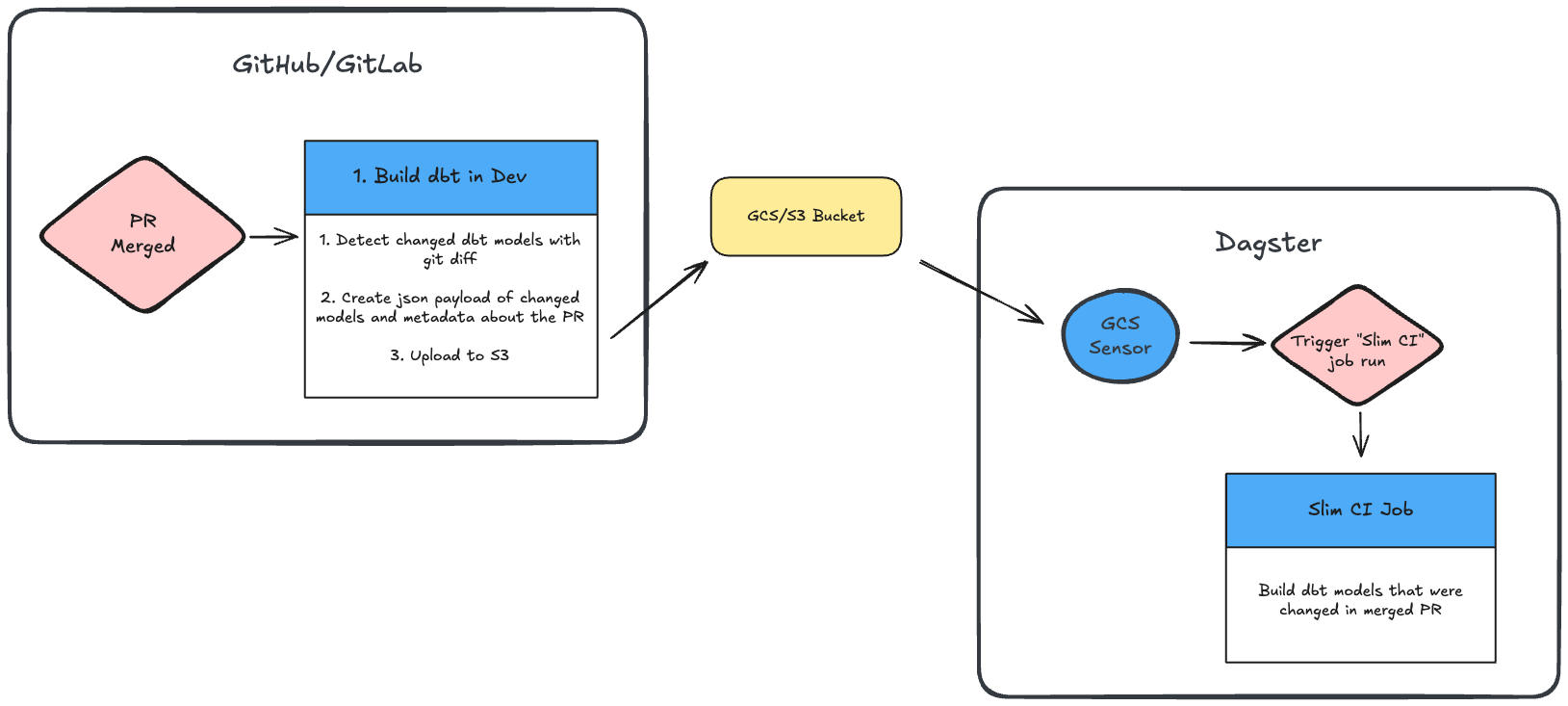
Architecture Overview
Rather than executing dbt prod runs directly in a CI job, this pattern uses some lightweight communication between your git provider and orchestrator. When a PR is merged, the CI pipeline generates metadata about change models and uploads it to cloud storage (e.g. GCS or S3). Dagster then monitors the GCS bucket for new metadata, and triggers a "Slim CI" job in Dagster to re-build only the selected models that were modified in the recently merged PR.
The flow looks like this:
- GitLab analyzes changed files and creates JSON metadata
- Metadata gets uploaded to GCS/S3 with structured paths
- Dagster sensor monitors for new metadata files
- Dagster automatically triggers dbt runs based on metadata content
- Complete audit trail is preserved for compliance and debugging
Implementation Details
The first step of this process is setting up a CI Job to detect changes and upload metadata to cloud storage. As a reminder, the example below is for GitLab and GCS, but the same approach could be easily adapted for GitHub and S3 instead. When a PR is merged, the CI job detects the dbt models that were changed, and stores that information in structured json along with valuable metadata from the PR (e.g. the PR number, branch name, timestamp of merge). That json payload is then uploaded to your GCS bucket with a partitioned path, so that it can be easily discoverable and picked up by your Dagster sensor.
When your PRs merge, a json payload like this one will be generated and uploaded to your GCS bucket:
{
"commit_sha": "g75hf625",
"branch_name": "my-example-branch-from-pr",
"merge_request_number": "105",
"timestamp": "2025-09-22T18:23:44Z",
"changed_models": [
"changed_model_1","changed_model_2","changed_model_name_3"
],
"total_changed_models": 3,
"ci_pipeline_url": "https://gitlab.[your_org].com/[your_repo]/-/pipelines/10001"
}
On the Dagster side, a sensor monitors the GCS bucket for newly uploaded metadata files. As you can see, each json file is uploaded to GCS in a partitioned folder based on the git SHA of the merge commit. This allows our sensor to just monitor the subdirectory of our bucket with the matching git SHA of the latest merge:
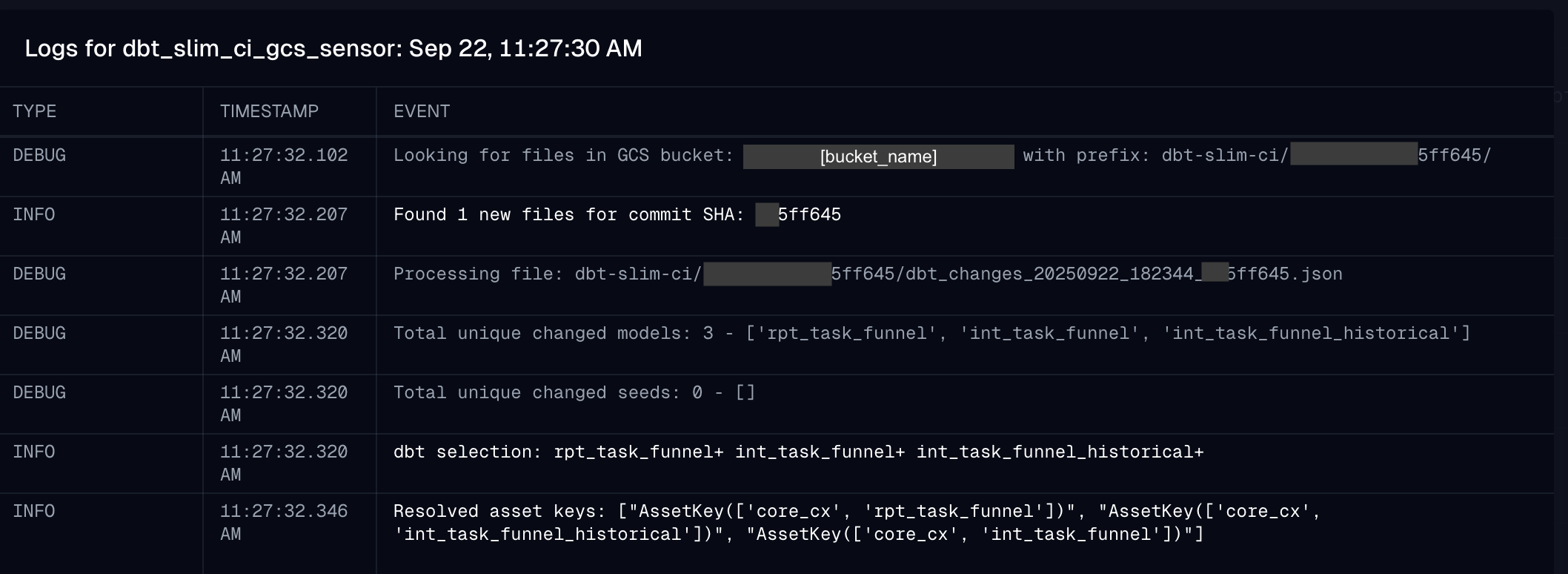
The sensor monitors for new files in our bucket within the subdirectory of our matching git SHA, and then processes the json to extract the list of changed dbt models. It then resolves the list of models to their matching asset keys in Dagster and launches a job run, passing through that list of models:
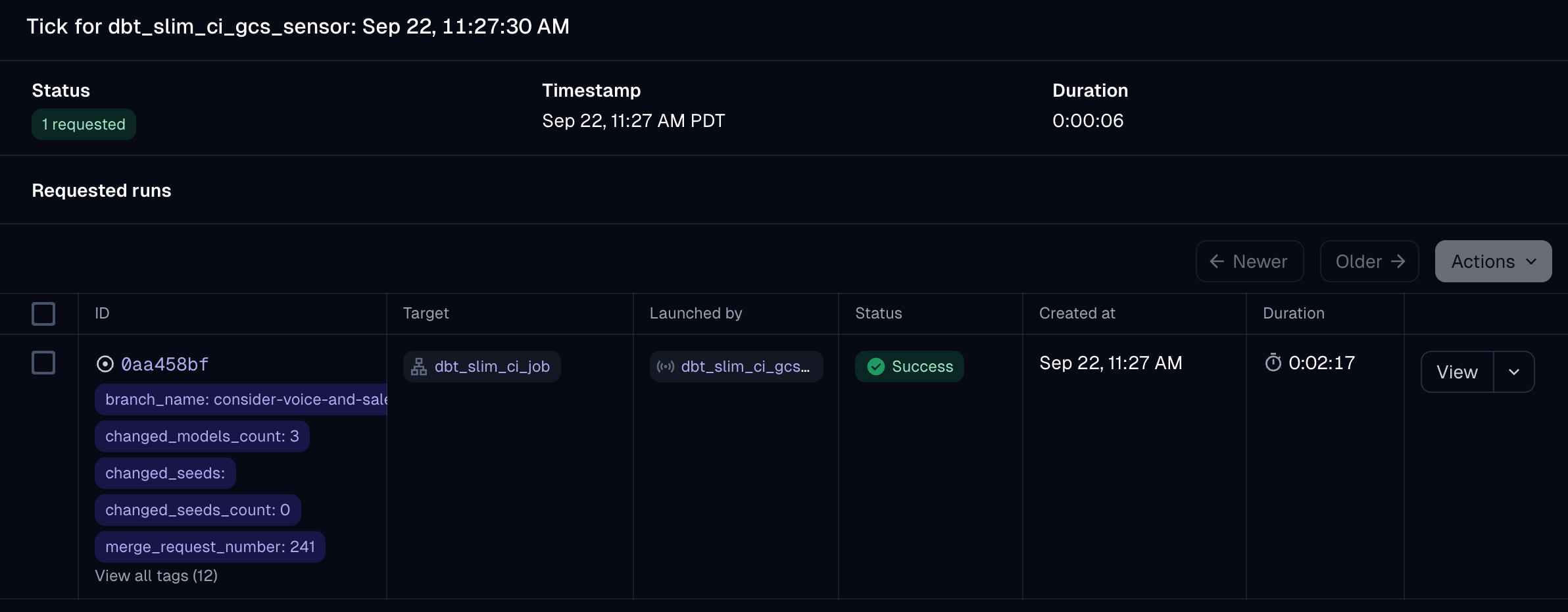
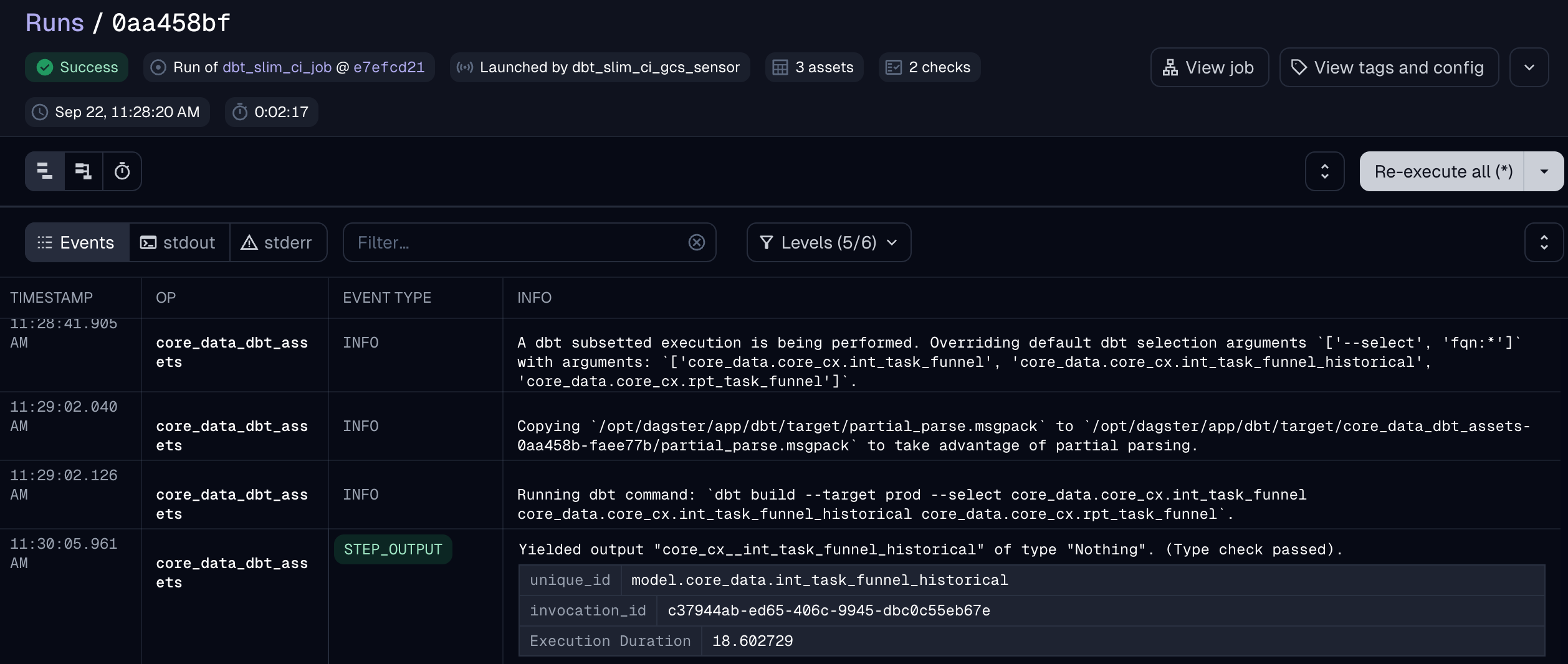
Benefits of the Orchestrator Approach
While this approach adds a couple extra steps, it provides a lot of benefits around security and observability.
Centralizing all of your prod dbt executions in a single place allows you to create a single source-of-truth to monitor and observe your dbt model runs in a central location. You can easily distinguish between when a model was refreshed by a scheduled job vs. when it was CI-triggered, and each Slim CI job includes the relevant PR number that was directly responsible for the job execution as context. We tend to set up Datadog integrations in our Dagster projects that emit Datadog metrics so that we can monitor the success/failures and execution times of all of our dbt models. If a model is built outside of the context of Dagster, we lose that visibility.
In the git provider CI-based solutions, your CI runners will need privileged read/write or admin access to operate on your production analytics database, which can become problematic when shared across multiple repositories or teams. With the orchestrator approach, your GitLab runner only needs cloud storage write access, while your Dagster deployment maintains the database credentials to perform operations against your warehouse. Additionally, GitLab and GitHub runners do come with an associated cost. While smaller organizations might not have to worry about this, GitLab runner minutes can be expensive for data-intensive operations, while your Dagster deployment runs on compute that is already optimized for these workloads.
Implementation Considerations
Hybrid Approach
If you're using something like Dagster for orchestrating dbt today, you can easily take a hybrid approach to combine the two methods:
- GitLab CI for Dev Validation: Run & test only the modified models in a development environment to catch potential issues before they're merged
- Dagster for Production Deployment: Once changes merge to main, use orchestrator integration to build the production analytics models, enabling consistency and centralized observability
When Each Approach Makes Sense
GitHub/GitLab-only solutions work well for:
- Small teams without a dedicated orchestration tool
- Simple dbt projects with straightforward dependencies
- Teams prioritizing CI simplicity over advanced observability
- Basic cron-based dbt execution patterns
Orchestrator integration becomes valuable with:
- Existing Dagster/Airflow management of dbt project
- More robust monitoring and alerting
- Security constraints requiring careful permission scoping
- Medium/larger-sized teams benefiting from centralized observability
Our general principle is that if you already use an orchestrator for production workflows, keep all dbt execution unified there. The operational benefits of single-source-of-truth monitoring typically outweigh the implementation complexity (which can be quite simple and elegant!)
In Summary
These are a few of our favorite approaches, but there is no single "right" solution. That's the fun of data engineering: you can solve the same problem in many different ways depending on the tools at your disposal and the ultimate goals that you are optimizing for. Whether you opt for simpler git diff approaches or full orchestrator integration depends entirely on your team's context, infrastructure, and needs.
A solid CI/CD process will greatly reduce errors and broken pipelines by ensuring that any dbt changes have been properly tested before they're merged, and will help ensure that any urgent changes you make are quickly reflected in your key analytics models in prod. What matters most is implementing something that gives your developers fast feedback loops while maintaining proper security and observability as you scale. You don't need dedicated proprietary tools to get this right—thoughtful engineering and creative use of existing infrastructure often work better long-term.
If you're just getting started with CI/CD for your dbt project or looking to upgrade to a more robust approach, hopefully these patterns provide some inspiration for a practical starting point. We're happy to chat if you want help thinking through what might make sense for your team, and we'd love to hear if there's another approach that works well for you!
1 Continuous integration (CI) and continuous delivery/deployment (CD)
2 An idempotent process will return the same result no matter how many times it is run