Data has evolved from being just a byproduct of business operations to becoming a core driver of value, innovation, and competitive advantage. Whether you're a…
- Finance leader measuring your KPIs
- Operations team trying to automate manual work
- Engineer building the next AI product
poor data quality remains the biggest barrier to realizing this potential… It's all garbage in, garbage out if you're not careful. Research from Experian indicates that organizations lose an estimated 15-25% of their revenue to unreliable data that breaks analytics, corrupts ML models, and leads to costly strategic mistakes. The problem isn't a lack of technology — it's the absence of enforceable agreements around how data gets produced and consumed.
So how do we prevent these costly failures? Data contracts.
What is a "Data Contract"?
A data contract is like a nutrition label on food packaging (ignoring the creative rounding of calorie counts). Just like the label tells you exactly what's inside and guarantees those contents meet FDA standards, a data contract tells you exactly what should be in your dataset and guarantees it meets your organization's standards.
In more technical terms, a data contract is a formal, machine-readable agreement between a data producer and one or more consumers that specifies structure, format, semantics, quality standards, and terms of use for the governed asset. These contracts function as an enforceable quality guarantee, designed to eliminate fragile handshakes, undocumented assumptions, and ensure that data is structured as expected. This promotes a paradigm shift from reactive data quality monitoring to proactive, preventive governance.
Data Contracts in Practice: Component Level Implementation
A robust data contract comprises several interconnected components that provide a holistic definition of a data asset — covering its physical structure, business meaning, quality expectations, and operational guarantees. As dbt (data build tool) has become the de facto standard for transforming data in the modern data stack with over 100k community members, this article will make an example of it. This section breaks down the anatomy of a data contract and demonstrates how to implement each part leveraging this widely adopted tool. Despite the specific tooling leveraged for implementation in this article, these generalizable concepts are widely applicable regardless of the transformation framework (i.e. dbt) used.
Here is a basic diagram of data contract implementation in dbt:
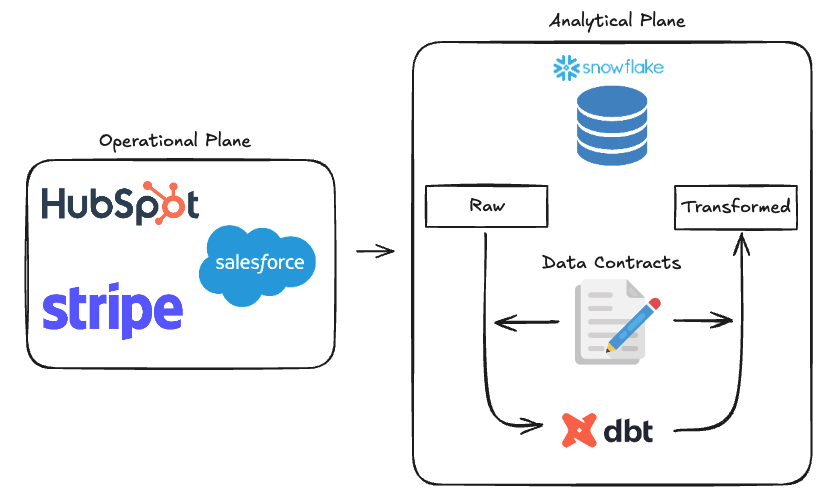
Schema: The Structural Blueprint
dbt directly enforces this structural blueprint using a feature called
a model contract. By applying the
argument of contract: {enforced: true} in a model's YAML configuration, you declare the exact "shape" of the model's
output. dbt then performs a "preflight" check before the model is built, comparing the columns and data types produced by the
model's SQL against the defined contract. With this implementation approach, if there are any mismatches – a missing column, an
extra column, or an incorrect data type – the model's build will fail immediately, preventing a non-compliant table from ever
being created. This shift-left
¹
The act of moving quality checks earlier in the development timeline—from production (right) to development and
testing (left)—to catch issues before they impact users.
approach catches breaking changes in development rather than production, safeguarding
downstream pipelines and maintaining trust in consumers' analytics.
YAML Code Example:
# In file: models/marts/dim_customers.yml
models:
- name: dim_customers
config:
materialized: table
contract:
enforced: true
columns:
- name: customer_id
data_type: int
description: "The unique identifier for a customer."
constraints:
- type: not_null
- name: first_name
data_type: string
description: "The customer's first name."
- name: signup_date
data_type: date
description: "The date the customer first signed up."
constraints:
- type: not_nullThe above configuration example mandates that the dim_customers model must produce a table with exactly three columns of customer_id, first_name, and signup_date all of which conform to their specified data types of int, string, and date respectively.
Semantics: The Business Context and Logic
While the schema defines the structure of the data, semantics define its meaning. This is where data contracts prevent the most common hidden failures: cases where the structure is perfect but the business logic is broken. For instance, the schema might enforce that order_date and fulfillment_date are both valid timestamps - but only a semantic rule can catch that an order was "fulfilled" before it was placed, signaling either a data pipeline bug or incorrect source system logic. Without semantic contracts, these logical impossibilities propagate silently through pipelines, corrupting metrics and eroding trust in analytics across the organization.
Where dbt contracts enforce schema before models are built, dbt tests validate semantics and business logic after models are created. These tests take the form of SQL queries that execute against the built model to verify its contents meet business rules and logical constraints. Let's examine two critical implementations: Referential Integrity and Business Rules.
Referential Integrity: Broken relationships between tables cascade into corrupted dimensional models and analytics. dbt's built-in relationships test can be leveraged to enforce the integrity of these relationships, preventing orphaned records ² Data entries in one table or system that lack a corresponding parent record in another table or system, breaking the expected relationship between them. .
YAML Code Example (Referential Integrity):
# In file: models/marts/fct_orders.yml
models:
- name: fct_orders
columns:
- name: customer_id
tests:
- relationships:
to: ref('dim_customers')
field: customer_idThe above test enforces the semantic rule that every customer_id in fct_orders must exist in dim_customers.
Business Rules: Beyond structural relationships, semantic contracts must also enforce domain-specific logic and constraints. For these complex business rules, dbt allows for custom (or "singular") tests — SQL queries saved in the tests/ directory that are expected to return zero rows. If the query returns one or more rows, the test fails.
SQL Code Example (Business Logic):
# In file: tests/fct_orders_shipping_date_after_order_date.sql
select
order_id,
ordered_at,
shipped_at
from
{{ ref('fct_orders') }}
where
shipped_at < ordered_atThe above custom test enforces the critical business rule that an order cannot be shipped before it was placed.
Data Quality Rules: Defining "Fit for Purpose"
This component establishes measurable standards for the data's reliability and integrity, ensuring it is fit for its intended purpose. These are concrete, verifiable rules that establish thresholds for metrics like completeness, uniqueness, accuracy, and volume.
dbt enforces these standards using both its native testing framework and powerful extension packages. Basic quality rules are handled with native generic tests like not_null and unique. For more sophisticated validation, the dbt-expectations package provides an extensive suite of pre-built tests inspired by the Great Expectations library.
To use dbt-expectations, add it to your package.yml file, as shown below, and run the dbt deps command:
# In file: packages.yml
packages:
- package: metaplane/dbt_expectations
version: 0.10.9Once installed, you can leverage over 50 advanced tests in your model configurations.
YAML Code Example (Multi-Layered Quality Contract):
# In file: models/marts/fct_orders.yml
models:
- name: fct_orders
tests:
# Quality Rule (Volume): Check if the daily number of orders is within a historical range.
- dbt_expectations.expect_table_row_count_to_be_between:
min_value: 1000
max_value: 50000
group_by: [order_date]
columns:
- name: order_id
tests:
# Quality Rule (Format): Ensure order_id follows the standard format.
- dbt_expectations.expect_column_values_to_match_regex:
regex: '^ORD-[0-9]{8}-[A-Z0-9]{4}$'
- name: order_total
tests:
# Quality Rule (Accuracy): Flag orders with unusually high values for fraud review.
- dbt_expectations.expect_column_values_to_be_within_n_stdevs:
standard_deviation_count: 4This example showcases how dbt-expectations enforces volume contracts (expect_table_row_count_to_be_between), format constraints (expect_column_values_to_match_regex), and statistical outlier detection (expect_column_values_to_be_within_n_stdevs), providing comprehensive data quality validation beyond what native dbt tests offer.
SLAs: Guarantees of Freshness and Availability
Service-Level Agreements (SLAs) provide operational guarantees about the data's timeliness and accessibility. This allows downstream consumers to build processes with confidence, knowing when fresh data will be available and receiving immediate alerts when upstream systems lag behind expectations.
dbt monitors data freshness SLAs for source data using its native source freshness command. In the source's YAML configuration, you can define warn_after and error_after thresholds. When you execute the command dbt source freshness, dbt checks the latest record in the specified loaded_at_field and alerts or fails if the data is staler than the configured thresholds.
YAML Code Example (Freshness SLA):
# In file: models/sources.yml
sources:
- name: production_database
tables:
- name: raw_orders
loaded_at_field: "updated_at"
freshness:
warn_after: {count: 12, period: hour}
error_after: {count: 24, period: hour}This above configuration defines an SLA for the raw_orders table. dbt will issue a warning if the latest updated_at timestamp is more than 12 hours old and will fail with an error if it exceeds 24 hours, indicating a breach of the established freshness contract.
Note that dbt source freshness must be invoked explicitly – it doesn't run automatically during dbt build or dbt run executions. Organizations typically schedule freshness checks independently (e.g. hourly) or as a prerequisite step in their orchestration pipelines to catch stale data before kicking off transformations downstream.
Governance and Ownership: Establishing Accountability
The final component is arguably the most important part of data management: the human aspect. Formalizing ownership in your data contract helps ensure clear accountability when things go wrong. Without explicit ownership, data incidents become prolonged investigations where teams spend valuable time debating who's responsible instead of actually fixing the problem quickly. Clear ownership metadata ensures alerts are routed to the right team and access controls align with data sensitivity.
Unlike schema and quality rules that dbt enforces automatically, governance is documented through the meta property in YAML files, creating a version-controlled record of ownership and sensitivity. This metadata surfaces in dbt's documentation and integrates with data catalog tools to establish clear lines of responsibility.
YAML Code Example (Ownership and Sensitivity):
# In file: models/marts/dim_customers.yml
models:
- name: dim_customers
config:
contract:
enforced: true
meta:
owner: '[email protected]'
data_sensitivity: 'PII'
columns:
- name: customer_id
data_type: intThe above configuration explicitly documents that the marketing_analytics_team owns the dim_customers model and
notes that it contains sensitive PII
³
Personal Identification Information
. This information is crucial for routing alerts and managing access control.
In Summary
The Data teams that work most effectively with product & engineering teams have learned that trust doesn't happen by accident. Data contracts represent how we intentionally engineer that trust – shifting from reacting to data fires to preventing them before they start.
Throughout this piece, we have seen how data contracts are more than YAML configurations and test suites. They are agreements between people – producers and consumers – that create clarity about what data means, how it should behave, and who's accountable when issues arise.
Implementing and properly enforcing data contracts offers real and immediate impact. Engineers stop getting paged at 2 AM for data issues. Analysts spend time finding insights instead of validating whether their numbers are trustworthy and accurate. Leaders make decisions confidently because they trust the data underpinning them.
As your organization grows and becomes more data-dependent, the cost of unreliable data compounds. Data contracts aren't just a nice-to-have – they are becoming table stakes. The organizations that embrace them early will have a meaningful leg-up in data quality, and their culture of effective data management can create real competitive advantage.
The tools are in place, and they're actually fairly easy to implement. While it might seem like a lot of overhead to set up, you can start small: begin with your most important models and continue adding resilience to your pipelines over time. It doesn't need to be an all-or-nothing approach — even a few well-placed contracts make a meaningful difference.