Background
Replo provides a low-code platform and marketplace to help businesses build Shopify landing pages and customizable e-commerce websites. With a strong group of investors (YCombinator, Figma Ventures, Infinity Ventures, and others), the company launched in 2022 and quickly grew to over 1000+ paying customers. Like many hyper-growth startups, they collect a vast amount of data from a variety of source systems, but experienced the difficulty of centralizing this data and drawing actionable insights without an established data warehouse and an easy-to-use ETL process.
Many startups in this position find navigating the landscape of ETL and data tools daunting, often unsure where or even how to start. This is the exact type of problem that Snowpack Data exists to help solve: we bring extensive experience across the entire data stack, and we love helping companies move from zero-to-one while building solutions that are robust and will scale with them as they grow.
Project Overview
We began working with Replo in March 2024, with the goal of implementing a full end-to-end data stack. This involved setting up and configuring: a data warehouse, data ingestion pipelines, a dbt project to manage transformations & business logic, and an orchestration tool to run their ELT process on a regular cadence. While building our solution, we kept the following principles in mind.
Goals for our Data Stack:
-
Keep costs low: Utilize open-source tools wherever possible to keep costs low and relatively stable month-to-month
-
Easy to manage: The tools implemented and their project configurations should be thoroughly documented and easy to understand, so that Replo's current engineering team can manage them without a dedicated data engineering team
-
Robust and scalable: Build it the right way so that this data stack won't need to be overhauled in three years. The end result should be a mature solution that a data engineer or data scientist would be happy to inherit once Replo hires their first data FTE
What We Built
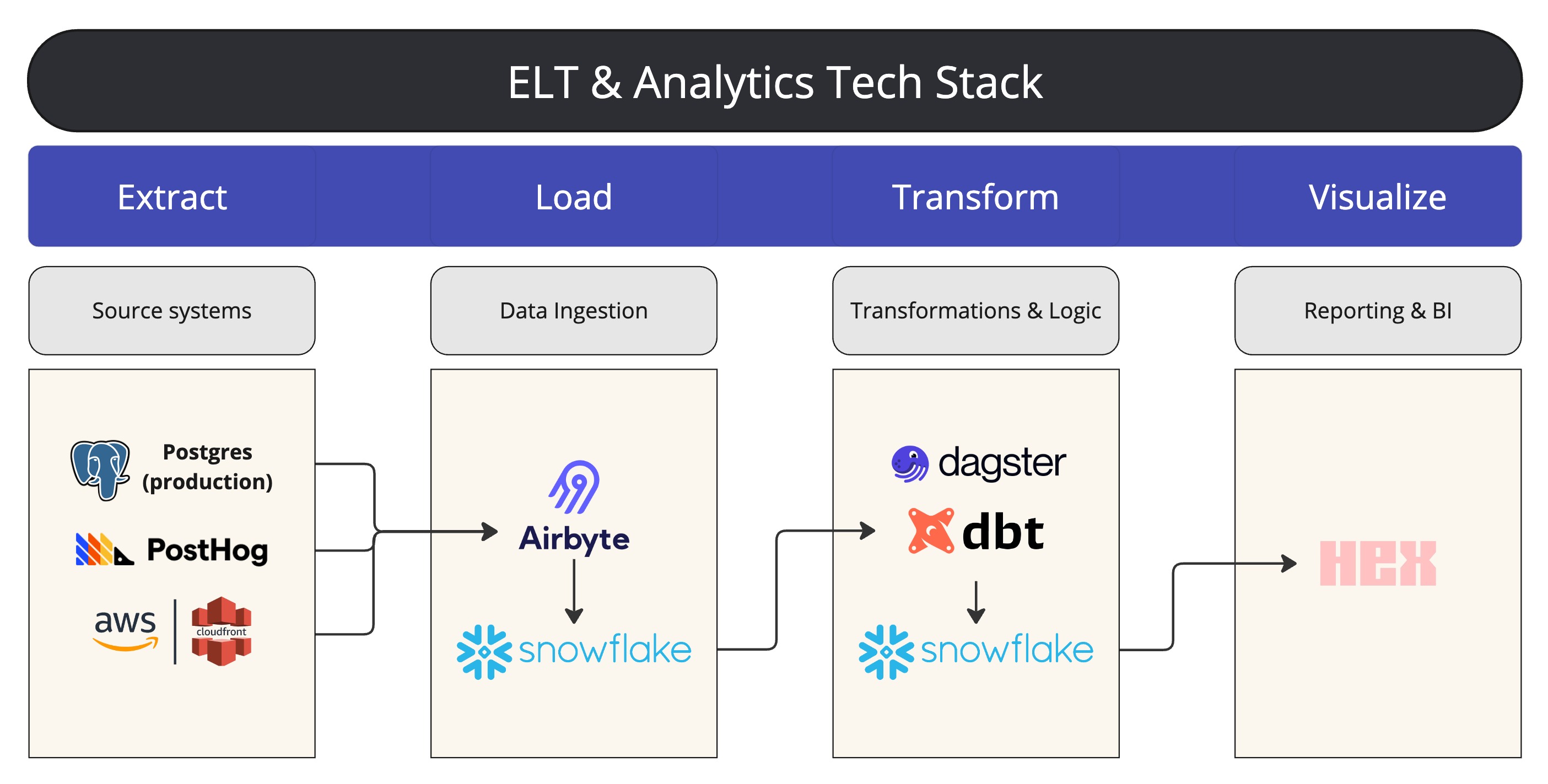
In order to achieve these goals, we implemented the following ETL¹ In a traditional context, ETL stands for Extract, Transform, Load. Modern data stacks typically follow more of an Extract, Load, Transform path, which is what we implemented at Replo. stack:
-
Snowflake Data Warehouse Setup & Configuration
We provided a vendor comparison and cost estimates to help Replo select a cloud data warehouse, and Snowflake made the most sense for their data needs. From there, we configured a Snowflake data warehouse to act as the central repository for Replo's data. This involved setting up the infrastructure, configuring databases and schemas, establishing role hierarchies, and setting up budgets and resource monitors to help monitor and control costs.
-
Data Ingestion via Airbyte
We integrated new data sources into Snowflake using Airbyte, an open-source data integration tool. Airbyte manages the "E" and "L" (extract and load) portions of the data stack, providing a user-friendly interface for users to set up and maintain data connectors and manage data ingestion with minimal (or no) coding required. In this phase of the project, we helped Replo set up connections to start ingesting data from various new data sources into their Snowflake data warehouse. The self-service component ensures that both their engineering teams and less technical data owners will be able to connect and sync new data sources moving forward.
-
dbt Project for Data Transformation
To manage the "T" (transform) portion of the ELT process, we set up a dbt project to enable users to transform data and create data models and tables in the data warehouse that are optimized for analytics and reporting. dbt (data build tool) is an open-source tool that allows users to manage and version-control their business logic as code, enabling teams to define a single source of truth for metrics, insights, and business definitions. This will help Replo standardize analytics and streamline management of their data lineage as they continue to build out the dbt project, establishing a strong foundation for data hygiene and data quality right from the start
-
Self-Hosted Dagster Implementation for Orchestration
We implemented Dagster, an open-source orchestration tool that enables users to build, schedule, and execute data pipelines. Dagster allows Replo to schedule and execute dbt jobs, monitor the freshness of tables and their upstream sources, and provides an intuitive UI for interacting with the dbt project. We wrote more in-depth on why Dagster and dbt complement each other so well in this follow-up blog post, where you can see the end result of this project in action. We self-hosted and deployed the Dagster project to AWS to ensure that it can handle increasing data volume and complexity, while keeping costs relatively stable month-to-month as Replo continues to grow (i.e. they are not tied to variable per-user pricing). Marrying Dagster with their dbt project provided an interactive UI and self-service capabilities for both expert and non-technical users to manage their analytics pipelines.
Outcomes
It's fairly common to see companies that are early in their data journey follow one of these two paths:
-
They hire their first data scientist before setting up a robust ELT process, resulting in that new hire spending their first year building infrastructure rather than focusing on actual "data science" projects. Even worse: many times the data scientist will say, "This isn't my job", and tell you to hire a data engineer, incurring even more costs and further delaying your data initiatives
-
They try to build an ETL pipeline themselves with their current engineering team, often creating a fragile bespoke solution that will need to be replaced sooner-rather-later, or overly relying on expensive managed solutions to simplify the setup process. This not only incurs significant opportunity costs by pulling engineers away from their core responsibilities, but also extends the time required to fully set up and understand the data infrastructure.
In contrast, Snowpack Data delivered a comprehensive and scalable data stack for Replo in just three months. Our solution (+ thorough documentation) reduced the barrier-to-entry for their current engineering team to understand and manage the pipeline moving forward, and saved them the substantial costs of hiring multiple full-time employees to build and manage this process. By leveraging open-source tools and self-hosting wherever possible, the all-in costs for their entire ELT pipeline (including Snowflake spend) project to be less than $500 per month, and will remain relatively stable even as Replo continues to quickly grow.
Taking the first steps towards becoming a data-driven organization is a great sign of company growth and organizational maturity. Building out your analytics capabilities should be an exciting endeavor and doesn't have to be daunting. Snowpack Data has extensive experience helping companies build cost-effective and robust data stacks in a fraction of the time it would typically take a full data team. If your company could use a little help getting started, come talk to us !