Introduction
When Hex announced their Semantic Model Sync feature in March, it immediately caught our attention. It offered something we hadn't seen before: the ability to query semantic models and metrics defined in your dbt Core project.
dbt's Semantic Layer product was a huge milestone for the data industry, but this feature is only available for customers of their dbt Cloud product offering. Since 2019, we have been early, happy users of dbt, and now help clients manage both their open-source and paid offerings. Many of the modern BI tools have since released integrations to dbt's semantic layer, but these naturally required dbt Cloud as well. Hex's announcement was the first that offered a solution that works for the (many) organizations that still use dbt's open-source core product. We were intrigued. And as longtime fans of Hex, we had to try it out ourselves to see how well it actually worked.
Ok, first of all: what's a semantic layer?
The 30,000-foot view of a semantic layer is that it's essentially a translator between your business users and your raw data. It sits between your data warehouse and the downstream tools where users can run queries from (e.g. a BI tool), and creates a unified definition of business concepts. Defining a metric in your semantic layer provides instructions to your downstream tools on how to construct the query and calculate the metric in a consistent and standardized way. A semantic layer allows your end users to just say "show me net revenue by region for the past 4 quarters", rather than having to recreate the logic for "net revenue" each time they want to calculate it (while remembering all of the nuances and edge cases that might go into it).
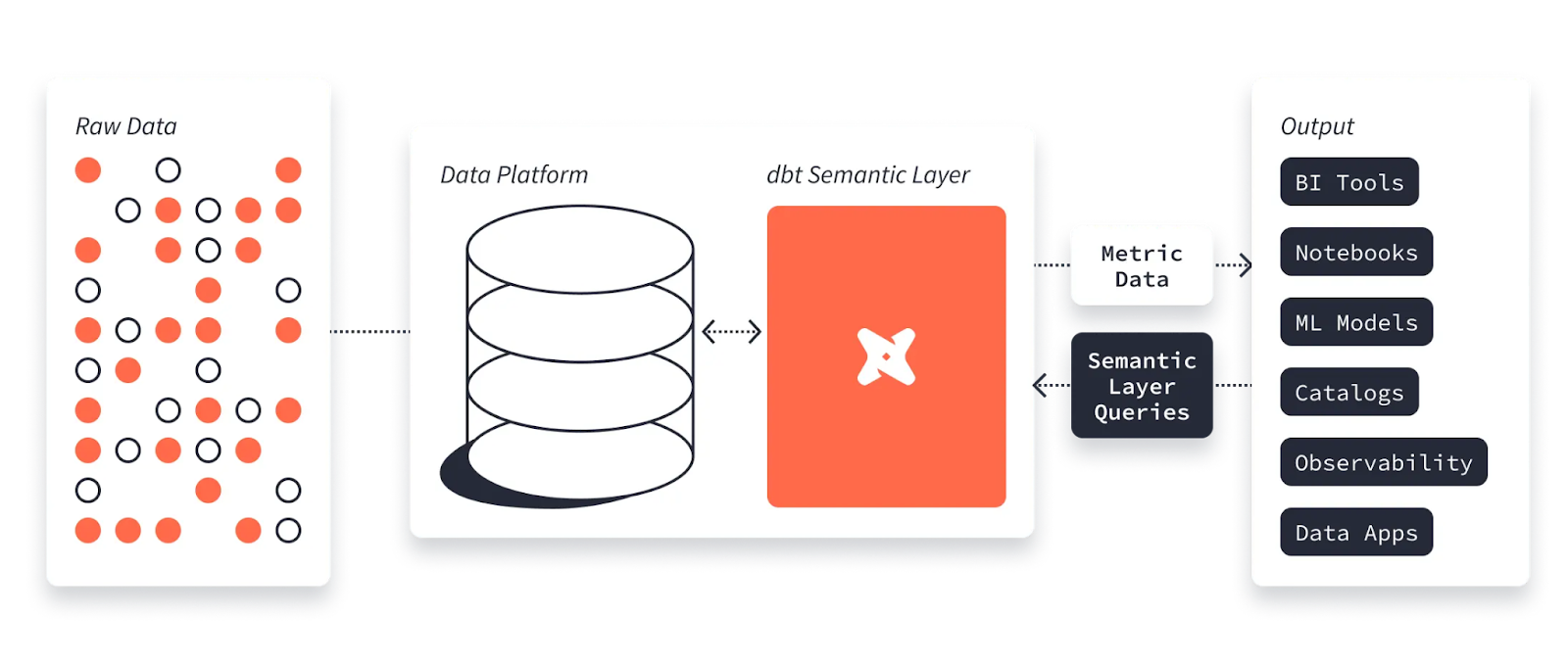
If you've worked in tech for long enough, it's almost guaranteed you've run into a situation like this at some point: your CRM dashboard displays different numbers for MRR than the monthly finance report. If you really dig into it, you might find some subtle differences in how your Sales team calculates the metric vs. the Finance team. You may realize both teams sum up subscription revenue, but your Finance team excludes churned customers.
A semantic layer solves this by encoding business logic centrally. You define MRR once (including exactly which fields to use, how to handle edge cases, and what constitutes a valid time period) and every downstream tool pulls from that same definition. Whether someone is building a dashboard in Tableau, running an ad-hoc query, or asking an AI plugin for last quarter's performance, they're all working with the same underlying calculation. The semantic layer handles the joins, aggregations, and complex logic that business users shouldn't have to think about.
The importance of a semantic layer will likely be elevated even further in the age of AI, which honestly may be the mostly compelling reason to start seriously thinking about semantic modeling if you are not already. As laid out in this excellent overview from Cube, "The semantic layer provides the necessary constraints and context that enable AI Agents to operate reliably and deliver trustworthy insights. It bridges the gap between raw data and business meaning, ensuring that AI's analytical prowess is grounded in a solid understanding of the organization's key concepts and metrics."
We're rapidly moving toward a world where business users will simply ask AI tools questions like "How has our customer acquisition cost trended over the past year across our customer segments?" For AI to answer these questions accurately, it needs to know exactly what you mean by "customer acquisition cost" and what exactly you're referring to as "customer segments".
Without a semantic layer, you're essentially asking AI to make assumptions about your business definitions every single time. That's a recipe for inconsistent (and potentially wrong) answers. But with a well-defined semantic layer, AI can tap into your organization's established "source of truth" for metrics, ensuring that everyone (human or AI) is working with the same underlying calculations and business logic.
The semantic layer + BI problem
The benefits of implementing some form of a semantic layer is clear: define your metrics in one place, and everyone benefits from the same definitions. But as Hex pointed out in their announcement, "the current state of semantic modeling in the data stack is a little weird."
On one hand, you have semantic layer offerings that sit directly in the BI layer. Looker is a prime example of this: they developed their own LookML language to define dimensions, measures, and relationships (i.e. your semantic models) against your database. While these can work well, they lock you into vendor-specific logic, and you can't reuse that logic in other tools or ad-hoc queries outside of your BI tool. We experienced the pain of this firsthand in past roles, where our data team maintained a large dbt project alongside numerous Looker Explores. If you ever needed to make an update to the underlying logic, you would need to make parallel updates in both dbt and LookML, and constantly battle inconsistencies from someone forgetting to update one system but not the other.
On the other hand, there are now standalone universal semantic layer products like Cube and dbt MetricFlow. These are undeniably powerful, vendor-agnostic solutions that integrate with most major BI tools. The major caveat is that they typically require paid cloud services to host them. In order to connect your typical BI tool of choice to your dbt semantic layer, you would need to be a dbt Cloud customer. This leaves out the enormous community of dbt Core users who don't want to pay for dbt Cloud just to access semantic layer functionality.
dbt's open-source product (Core) technically still supports MetricFlow, but it has felt slightly... useless up to this point. Without a way to easily fetch and surface those metrics to business users, what's the real value? Only being able to query your metric models via the command line isn't exactly the self-service analytics dream that most teams are chasing. Up to this point, it has felt like there's no real point in implementing MetricFlow and semantic modeling in dbt unless you're a dbt Cloud customer.
Hex's different approach
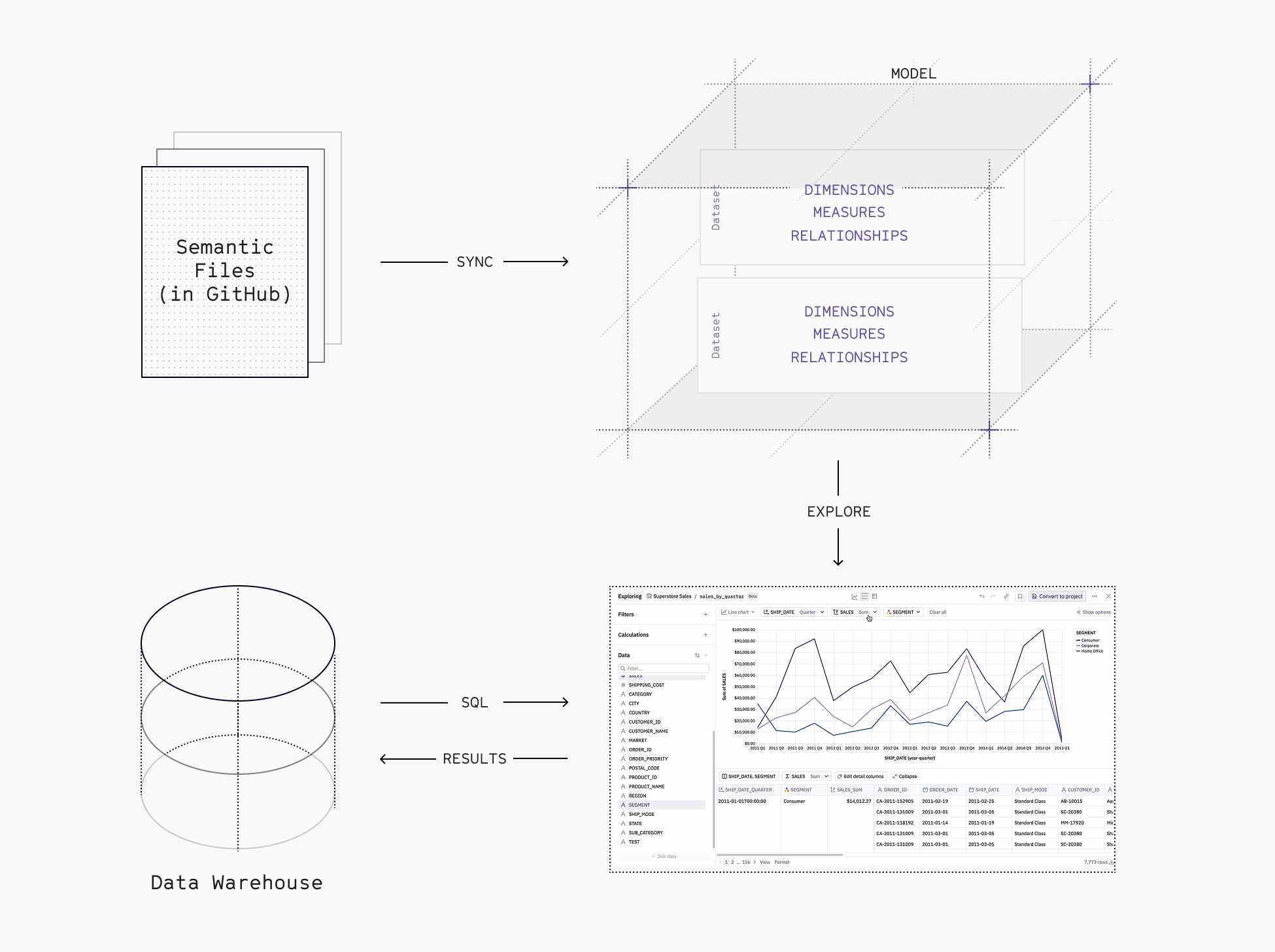
Unlike other BI tools that directly connect to your dbt Cloud project to import your semantic models, Hex uses a clever additional layer of abstraction: it connects to the GitHub repository (or other git host) where your dbt semantic models live. Hex then imports semantic models stored in GitHub, and translates the specs into measures, dimensions, and joins. This creates and syncs a semantic model within your Hex project, so that all users can reuse the same sets of dimensions, measures, and joins that you have already defined in your dbt project.
Your dbt project remains the source of truth for metric definitions, and updates will be synced to your Hex data model whenever you merge a PR in your dbt repo. No more manual interventions or maintaining two sets of definitions required.
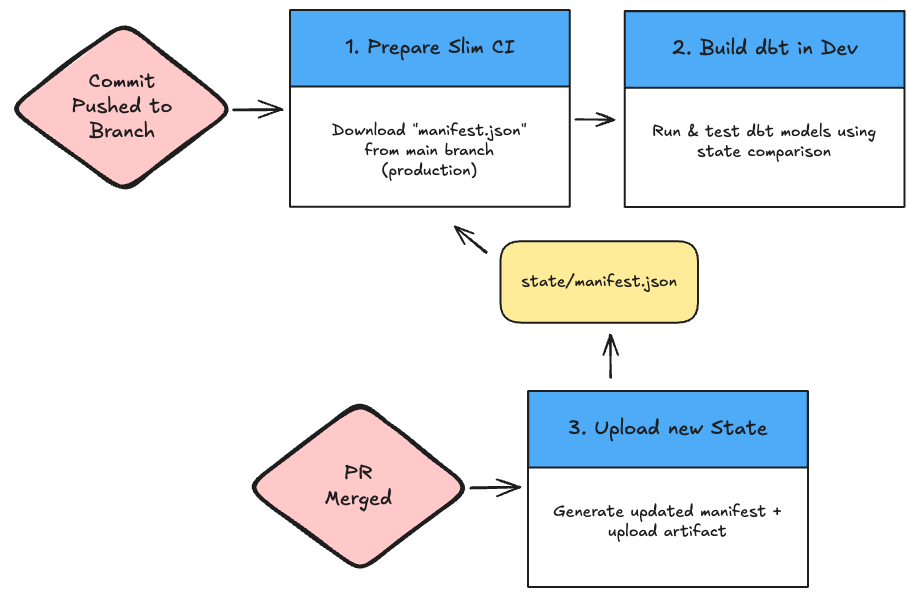
There are some quick setup steps required to prep your dbt project and GitHub repo before you can begin syncing your semantic models. You'll need to add some additional Hex-specific metadata into your dbt models, create an API token in Hex, and add a GitHub action to your project. Once set up, the GitHub action will send the contents of your repository to Hex whenever you merge new code.
How it works in practice: a quick demo
We tested this out in a dbt Core project using a dataset for NBA stats over the past 10 years. We set up a MetricFlow semantic model and added several metrics to calculate basic box score statistics for players and teams.
After completing the setup steps mentioned above, we merged a change into our dbt project and inspected the GitHub action. Our first attempt failed, but luckily the output of the workflow provided some helpful information to resolve it:
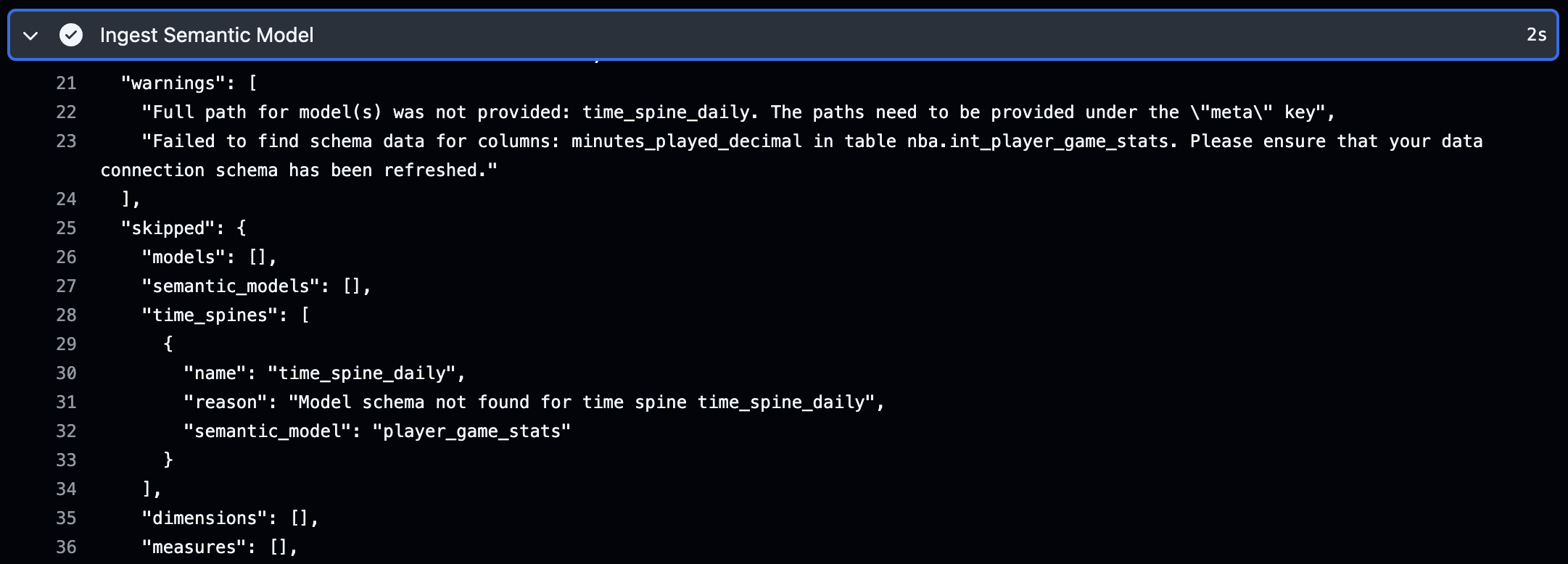
The warning laid it out pretty clearly, so we realized we just needed to add an additional Hex-specific config under our "meta" key for one of the dbt models. After pushing the fix, we see the "all-clear". Our semantic model was successfully ingested with no warnings and no models skipped:
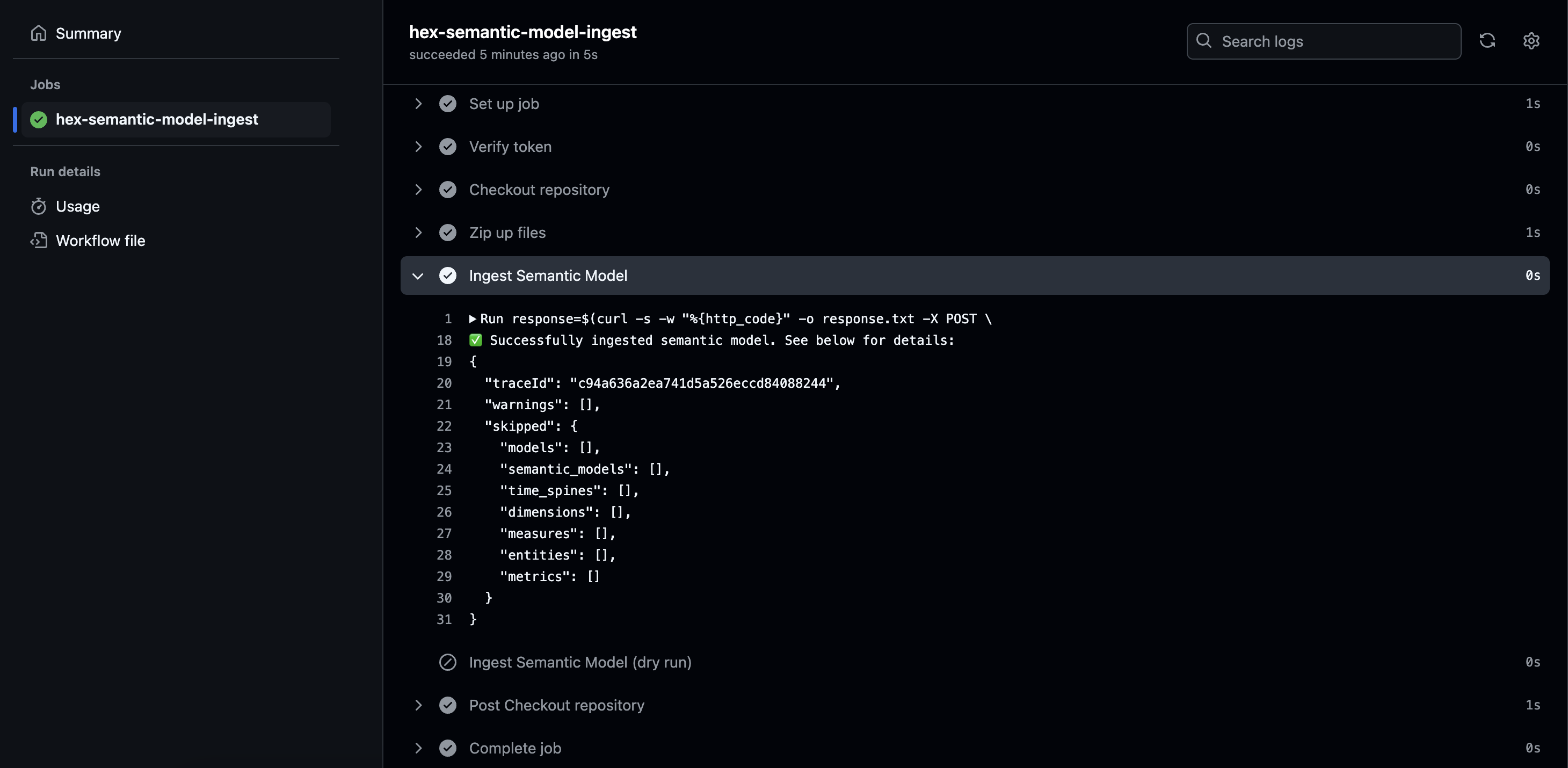
Great! Let's see what happened on the Hex side. In the Data Browser of our Hex project, we now see our semantic model listed under the "Data Models" tab. Once we click into it, we can see all of our defined metrics, the underlying expression used to calculate it, and descriptions for each metric:
Now that we've confirmed we can access our semantic model in Data Browser, we can begin using it by either by clicking "Explore", or by creating a new Explore cell in a dashboard. The "Explore" UI looks and feels pretty familiar if you've ever used Looker (or similar BI tools). To test it out, I wanted to find the most 3-pointers attempted by a team in a season. By just dragging and dropping the relevant dimensions (NBA season, team name) and measures (3PT attempts, 3PT makes, and 3PT percentage), I was able to quickly identify that the Houston Rockets set the record in 2018 with 4,377 attempts:
Hex also includes native drilldown functionality, so you can further drill into any Explore query. If we drill into the top season to see which players on the Rockets attempted the most 3-pointers, we can see that James Harden shot almost 500 more than his next closest teammate! If we further drill into Harden's metrics, we can then quickly see that his 3-point percentage dropped from 38% to 35% in home games vs. away games:
Pretty cool. And pretty painless. We were able to quickly spin this up and start delivering insights in minutes. We didn't have to write extensive LookML to create our data model and dimensions/measures, and we didn't need to set up any kind of custom logic to enable hierarchical drilldowns. When adding new metrics or updating definitions, we didn't have to make updates in both our dbt project and our BI tool. It was all just automatically synced from our dbt project's semantic model, enabling our dbt project to serve as the single source of truth.
Why this matters for Data teams
While this isn't a magic silver bullet that will solve all of your Data team's problems, it certainly is a huge development for dbt Core users. You can now start seeing the benefits of a semantic layer without being a dbt Cloud customer, duplicating work, or locking yourself into proprietary modeling languages specific to your BI tool. Teams using dbt Core finally have a practical way to start seeing the value of codifying source-of-truth metrics and semantic models within their dbt project.
This timing also couldn't be more relevant. Just this week, dbt Labs announced major changes to their product strategy with the introduction of dbt Fusion, their new "next-generation engine" that promises faster performance and a suite of new features. While the product and technical improvements are exciting, there's an elephant in the room that has the data community wondering what this means for the future of dbt Core.
Reading between the lines of the announcement, it seems increasingly clear that dbt's roadmap is steering toward a future where the most compelling features live exclusively in their paid offerings. The semantic layer was an early example, and we'll likely continue to see a pattern where innovation happens first (and sometimes only) in the premium tiers. For teams that have built their entire data stack around dbt Core, this creates a pretty uncomfortable question: how long before we're forced to choose between staying on an increasingly stagnant open-source version or paying for the paid Cloud offering to access the new latest and greatest features?
This is where Hex's approach becomes even more valuable. They've built a bridge that lets you access semantic layer functionality regardless of which dbt product you're using. It's the kind of vendor-agnostic thinking that gives teams real optionality, which feels increasingly valuable as the data tooling landscape consolidates around paid platforms.
It's also worth noting that Hex recently acquired Hashboard, and announced plans to begin incorporating some of Hashboard's best features around self-serve BI, semantic modeling, and data visualization. It's still early days, but we're excited to see how the semantic model and Explore features will evolve as part of this acquisition. Hex was already a favorite of many data science and analytics teams for their flexible notebook environment, but the acquisition, recent launches like Semantic Model Sync, and their freshly announced Series C signal that Hex is becoming a real challenger to some of the largest tools in the BI space.