Data Engineering is a nebulous term for a role that varies wildly from org to org. As you think about growing your data team you will inevitably come across this term and think about hiring a data engineering team. In this article we want to provide a framework for understanding the responsibilities of a data engineer, as well as define a standard org model for a data engineering team. We'll aim to answer 4 key questions:
- What are the key functions of a data engineering team and the roles of the staff?
- What are their boundaries with other teams?
- Who should they report to and what are the consequences of that decision?
- How do you develop a roadmap for a data org?
Key Functions of Org and roles of Staff
Data engineering sits squarely in the midst of role overlap between engineering, data science, and analytics. The scope of their role may vary in depth with these orgs from organization to organization. Ultimately the data engineering team will support the efforts of all three of these other technical orgs, however it's naive to assume that their role will have an explicit boundary.
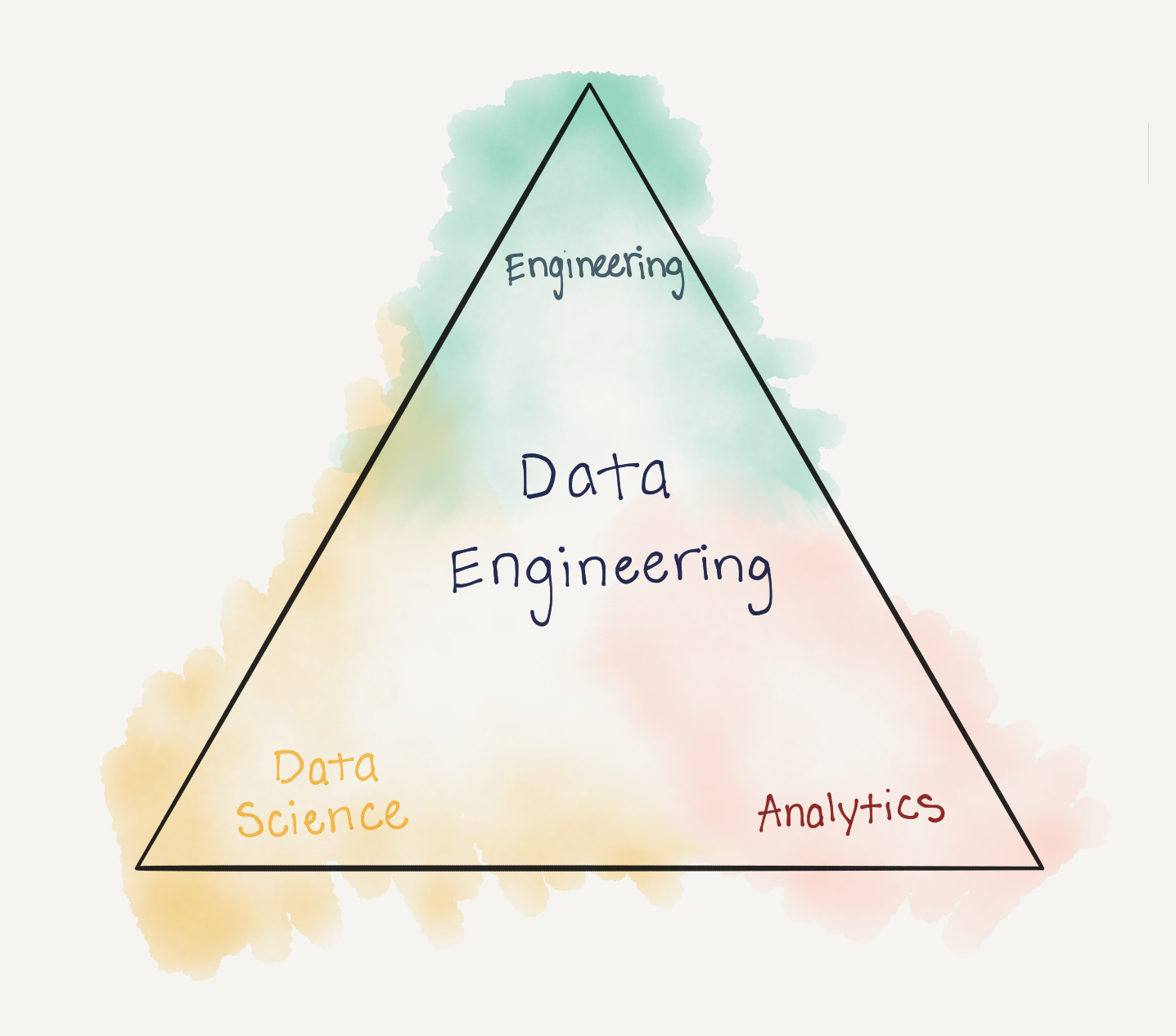 The Role of Data Engineering situated between Engineering, Data Science, and Analytics
The Role of Data Engineering situated between Engineering, Data Science, and Analytics
The data engineering team is primarily responsible for five pillars of tasks.
1. Data Ingestion
Ingestion is the process of moving data from various sources into a cloud data warehouse. It usually involves managing a platform service or a series of scripts that connect to various API endpoints and pipe data into your company’s data lake at regular intervals. The data engineering team is responsible for both building and maintaining this pipeline, a task that will continue to increase in scope as the complexity of the organization increases.
2. Data Processing and Cleaning
Like any raw material, once data is piped into the data lake, it needs to be cleaned of any errors, formatted, and tested for quality. Data engineers are responsible for writing scripts that test and format fresh data being piped into the database into a series of base models in the database that can then be used to build consumer models–data tables that contain business logic that are usable for analysis or are pre-formatted for further production use like AI/ML modeling.
3. Consumer Modeling
Consumer modeling is the process of adding business logic to the base models and formatting them to be used for consumption. This is the final step in the “processing” phase of the data lifecycle before data gets shipped out of the database and piped into reports, dashboards, or AI/ML models.
This process is often shared between data eng and analysts, with engineers building net new data assets, and analysts altering and maintaining those assets as needed as business requirements change over time.
4. Data Systems Design
In cases where a company is generating its own proprietary data–for example, by tracking user behavior on their app–data engineers will partner with software developers to ensure that data is passed cleanly to the database and that it contains the information needed to make it usable by other systems.
Data engineers will also help with data design in cases where a company wishes to connect data across multiple products or make its proprietary data available to clients via an API.
5. Data Governance and Security
Data engineers are responsible for implementing data governance and security policies for the organization. They manage access permissions to data sets, as well as the company’s suite of data tooling, actively manage load on database systems, and track costs in real time with observability software.
They also are responsible for and/or partner with infosec to facilitate security processes like PII masking, tracking data assets and user behaviors across nodes in the company’s data network.
Data Engineering's "Hats"
Collectively these responsibilities can be split into two tactical functions or "hats" that the team wears
Data Infrastructure and Pipeline
This function focuses on building and maintaining data infrastructure within the organization. It is typically earlier in the lifecycle of data in the company and might interface more closely with engineering than it does other teams. It usually involves:
- Data ingestion
- Data processing and cleaning
- Consumer data modeling
- Data systems design (api development, event tagging, data processing)
Database and Systems management
This function involves managing the process by which people and machines gain access to send data to and receive data from your company’s proprietary data systems, keeping your company’s data services running in real time, and tracking the costs associated with your data tools and properties. This involves managing tools and processes such as:
- User access permissions
- Data sharing
- Observability
- Cost tracking
- Security and regulatory compliance
Specializations
Many data engineers have worked across both of the above functions. In a smaller organization with 1-2 data engineers, it’s common for both these roles to be filled by the same person or group, but in larger organizations where it’s common for many people to require access to the data at the same time from different places, there will generally be engineers that specialize in one area vs. the other.
An alternative for larger (but still lean) data eng teams is to have the data engineering manager role be responsible for database and systems management (particularly where cost tracking and metrics are of concern), and the data engineers are responsible for infrastructure development.
The above is a preferred structure because it optimizes the centralization and distribution of engineering resources. In this model, your security and cost-center concerns are the responsibility of one person. As an executive, you have only one point of accountability for data engineering, the same point of contact for security concerns and the same source of truth for data service performance.
At the same time, it leaves your engineers free of dealing with tickets for new access permissions and other clerical issues, and allows them to be flexibly distributed across the projects or teams that require them most at a given moment.
Boundaries with other teams
Data engineering is fundamentally a service function both in the data org and in the larger organization. They exist to facilitate the transfer of data from source systems to downstream data products built by software engineers, data analysts and business users.
This is why data engineering teams operate best using engagement models–written agreements across teams, like contracts, that set the rules for collaboration on projects (strategic engagements) and set standards for day-to-day operational interactions (i.e. clear communication models, SLAs, On-Call services, etc.)
Practical limits of the data engineering role
In general, data engineers are not involved in the deployment or management of the end-products–if the product is a series of metrics and a dashboard, that responsibility falls to the data analytics team. If the product is a new feature for the company’s web application, the software engineering team is responsible for it. For a new ML/AI model, the data science team will take responsibility. Instead, data engineers serve these teams as partners in their development process–ensuring these teams have access to the data they need to do their jobs.
In practical terms: Consider the placement of your data engineering team in the context of your business–if it is heavily software development-focused, you’ll want to ensure there are clear engagement models for the product team, the software engineering team and the data eng team that enable them to work effectively–the same if it is sales-focused, etc.
Engagement models
Your data engineering team should develop an engagement model with every team it works with. It should also develop policies and processes to manage interactions across teams, as well as facilitate communication with the rest of the company.
Engagement models should define and establish norms for cross-team collaboration using methods like:
- Slack channels
- On-call hours & office hours
- Intake processes for new requests
- Standard SLAs
- Shared key metrics
- Weekly leadership updates
In addition, engagement models should include processes for prioritization and execution of tasks, these will look very similar to traditional engineering teams:
- Backlog grooming
- Prioritization sessions
- Project planning
- Task assignment
- Retros and feedback
- Project & product design docs
Leadership Structure
Data engineering generally sits under one of two org umbrellas: engineering or data analytics. Engineering usually rolls up to the CTO but data analytics groups tend to sit under whichever business unit is responsible for generating revenue. In SaaS companies this usually puts them under the CTO, but in other models it’s not uncommon to seat them under:
- The CRO if the company is sales/revenue growth focused (i.e. B2B SaaS)
- The COO if the company is focused on operational efficiency (i.e. logistics)
- The CFO if the company is focused on cost reduction/revenue increases (i.e. consumer-products)
The image below shows three org models composed of data engineering (ENG) and data analytics (DATA) teams. Each is viable depending on the stage of growth of a company and its organizational requirement. The data engineering and larger data organization’s structure will change as the company matures.
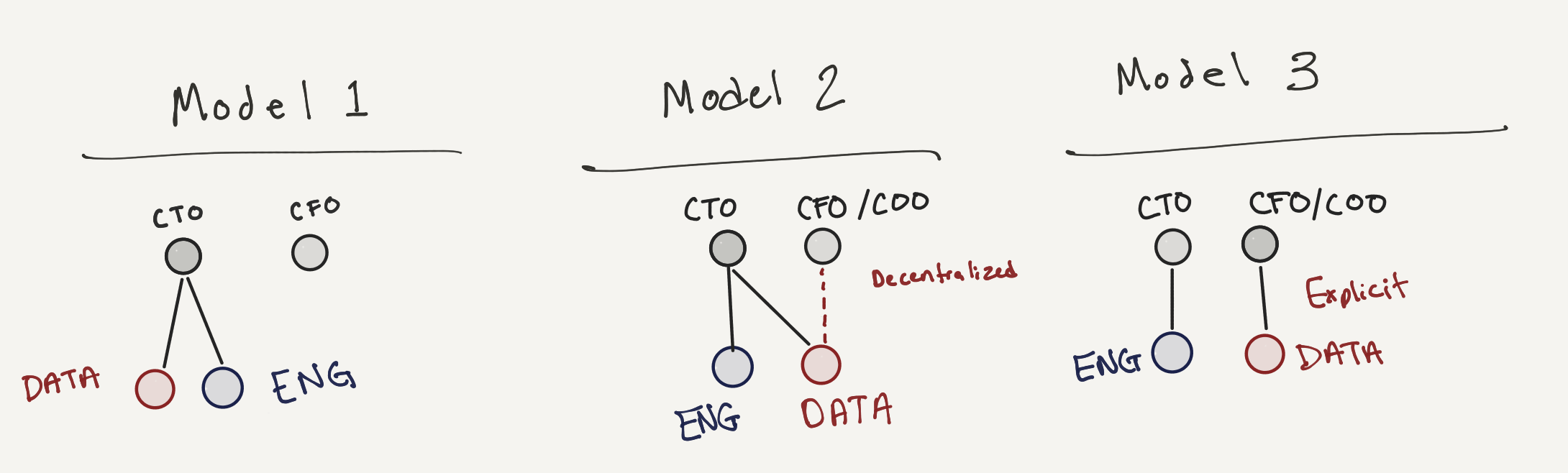 Sketch of three models of org reporting structures
Sketch of three models of org reporting structures
Model 1: Early/mid-stage startup
The primary goal of companies in this stage is generally to move fast and grow as much as possible. Centralizing the data team under a specific executive (in this case, the CTO) is the quickest way to ensure executive accountability for your data infrastructure development early on–as well as ensures alignment across the two core functions in the data org (analytics and data eng) with the software engineering org.
Model 2: Established business undergoing data transformation
In older, more established companies that are undergoing data transformations, adoption is an important factor in determining success. Many companies are slow to adopt new data technologies, and the introduction of databases and dashboards, or ML or AI models can be met with skepticism.
In these cases, we keep the engineering team centralized under one executive (again, in this example: the CTO), while placing the data team on another executive’s–or across multiple executives’--P&Ls. Effectively, this is giving your execs a dedicated analyst or analyst team with the sole responsibility of fulfilling their data needs.
Assuming your data engineering team has set up your infrastructure well, this structure allows the analysts to communicate directly with stakeholders as part of their chain of command, and quickly generate analysis or reporting for stakeholders.
This can be an extremely effective method of evangelizing users that are new to the data space or that may otherwise be resistant to a cultural shift towards data-backed decision-making. On the other hand, this structure can be dangerous if drift across teams is not managed over time. Having analysts on different teams that don’t communicate often leads to the creation of multiple sources of truth, which in turn leads to loss of trust in data. Furthermore, it is difficult to walk back if you need to re-centralize the data team into one single business unit.
Model 3: Modern mid-market/enterprise firm
A fully modernized firm operating with data products at scale uses a structure that balances the use of centralization of services where required with the distribution of analyst resources as needed. Its focus is on making data “self-serve”, meaning empowering the organization to access and use data for any purpose they require.
Their data engineering teams are fully centralized under one executive, as they manage infrastructure dev and maintenance as well as data security and access–processes that should be centralized to function effectively. The data analytics teams are under the same P&L as the data eng teams–meaning they have the same executive leader, but their services are distributed across the business units in dedicated teams. This structure allows a single data leader to manage alignment of priorities across the data organization (both eng and analytics), which is vital to protecting the quality and integrity of a company’s data. It also allows other business leaders to “adopt” their dedicated analysts as part of their team and integrate them into their functional workflows. This gives the data analyst business context necessary to be effective, while allowing the analytics leader the ability to provide air cover and challenge individual requests when they conflict with larger company priorities.
Additional Note: In large, highly tech-enabled firms, data engineering may also have an additional component of engineers known as ‘analytics engineers’, who are distributed across teams to help them build out their own data assets. Cases like this usually are only relevant to companies with platform technologies that have multiple databases and products in their portfolio. In these cases, Eng and Analytics remain consolidated under the same leader, on the same P&L. You’ll often see organizations that use this method do so by defining a separate role called “Analytics Enablement” with the core purpose of making data accessible.
Centralization vs Decentralization
There is a lot of content on the internet that debates the merits of centralizing vs. decentralizing your data teams. This is an ongoing debate in the data industry that is often used to generate marketing content. It’s better to think of centralization and distribution as tools, where distribution drives data proliferation across the company, and centralization ensures quality and security. The goal is to balance the two forces to maximize both ease of access to data (distributed), and data quality and integrity (centralized).
The Data Engineering Roadmap
Designing a roadmap for the data engineering organization is just a matter of connecting the dots across this document and consists of the following steps:
Assessing the existing data staffing and technology assets of the organization
- This includes costs associated with various tooling decisions as well as operational costs related to storage and compute.
- It also includes identifying gaps or overspending in your staffing model.
- The focus of this step is on identifying areas for cost-reduction and areas that need additional investment.
Developing a plan for the future state of the data organization
- Based on the assessment, develop a plan for the future state of the data organization that includes a staffing model, a technology stack, and a roadmap for the next 12-24 months.
- Include in this plan a set of KPIs that will be used to measure the success of the data organization.
- Include in this plan a set of engagement models that will be used to manage interactions across teams.
Conclusion
We hope this was a good introduction to the role and scope of data engineering at modern organizations. We'll be following up on this article soon with a more tactical discussion about organizational structure and the tradeoffs between centralized and decentralized data teams.